Prismer: A Vision-Language Model with Multi-Task Experts
by Shikun Liu, Linxi Fan, Edward Johns, Zhiding Yu, Chaowei Xiao, & Anima Anandkumar
We introduce Prismer, a data- and parameter-efficient vision-language model that leverages an ensemble of diverse, pre-trained task-specific experts. Prismer achieves fine-tuned and few-shot learning vision-language reasoning performance which is competitive with current state-of-the-arts, whilst requiring up to two orders of magnitude less training data.
Behind the Paper
Prismer is my internship project with NVIDIA Machine Learning Research Team. As with many of my past research projects, we initially set out with an overly ambitious goal, of designing a multi-modal generative framework >.< This is to create a system that could perform "any-directional" multi-modal generation tasks, such as image-to-text, text-to-image, depth-to-image, image-to-depth, and even (depth+segmentation)-to-image, where the model to solve each task would be initialised with a separately pre-trained domain expert. However, we quickly realised that the complexity of this research was too much for an internship project, because we have to accommodate the design of each model to make them compatible with each other, and also need to design a training scheme that can fine-tune all these models simultaneously.
As a result, we shifted our focus to a more specific task: multi-modal reasoning. This still allowed us to utilise a diverse pool of pre-trained models to provide useful domain knowledge, but without the need to heavily modify the network architecture of each model. This idea eventually led to the development of the Prismer project as it is.
The concept of "model ensembling" is very appealing, for which I was personally particularly inspired by the success of Socratic Models, which demonstrated that a wide range of multi-modal tasks could be achieved in a zero-shot manner by simply connecting them together using "language as the universal control interface". This similar concept has also been shown to be effective in the widely popular ControlNet (but in a slightly different perspective), which provided conditional multi-modal control for the Stable Diffusion model, only requiring some lightweight fine-tuning. Prismer was designed to follow this similar direction and explore how to better utilise pre-trained models when building a new model, particularly with multi-task and multi-modal capabilities.
Scaling up the model has become the easiest and the standard practice to improve the state-of-the-arts. This was first shown in the GPT model series for general-purpose language understanding, and has recently been applied to other domains, such as in vision and robotics. While I have to admit that "scaling up" is the major and essential factor of the great success in NLP, accompanied with the surprising emergent abilities only being shown in very large models, it's extremely difficult and probably also not affordable to simply train a multi-task multi-modal model as in a singular and unified architecture design. First, the multi-task learning needs to avoid negative transfer which is a well-known problem that has been the focus of my research for some time. And second, the multi-modal training data are extremely difficult to collect and most of the time do not exist. With the aim of including more and more tasks and modalities in a unified network, it is simply not feasible to re-train a fixed, large-scale model from scratch, every time to include a new task.
Building on the concept of "model ensembling", I hope that Prismer would become one of the first works to explore effective multi-modal learning strategies to tackle the aforementioned challenges. While I am not sure if this is the right direction at all, I do hope that Prismer will bring some fresh thinkings to the design and development of multi-modal foundation models for the future.
Shikun.
Introduction
Large pre-trained models have demonstrated exceptional generalisation capabilities across a wide range of tasks. However, these capabilities come at a hefty cost in terms of computational resources required for training and inference, as well as the need for large amounts of training data. The problems in vision-language learning are arguably more challenging. This domain is a strict super-set of language processing, whilst also requiring extra skills unique to visual and multi-modal reasoning. A typical solution is to use a massive amount of image-text data to train one giant, monolithic model that learns to develop these task-specific skills from scratch, simultaneously, and within the same generic architecture.
Instead, we investigate an alternative approach to learn these skills and domain knowledge via distinct and separate sub-networks, referred to as "experts". As such, each expert can be optimised independently for a specific task, allowing for the use of domain-specific data and architectures that would not be feasible with a single large network. This leads to improved training efficiency, as the model can focus on integrating specialised skills and domain knowledge, rather than trying to learn everything at once, making it an effective way to scale down multi-modal learning.
To achieve this, we propose Prismer, a visually conditioned autoregressive text generation model, trained to better use diverse pre-trained domain experts for open-ended vision-language reasoning tasks. Prismer's key design elements include, i) powerful vision-only and language-only models for web-scale knowledge, and ii) multi-task vision experts encoding multiple types of visual information, including low-level vision signals such as depth, and high-level vision signals, such as instance and semantic labels, as a form of auxiliary knowledge. All expert models are individually pre-trained and frozen, and are connected through some lightweight trainable components, that only comprise roughly 20% of total network parameters.
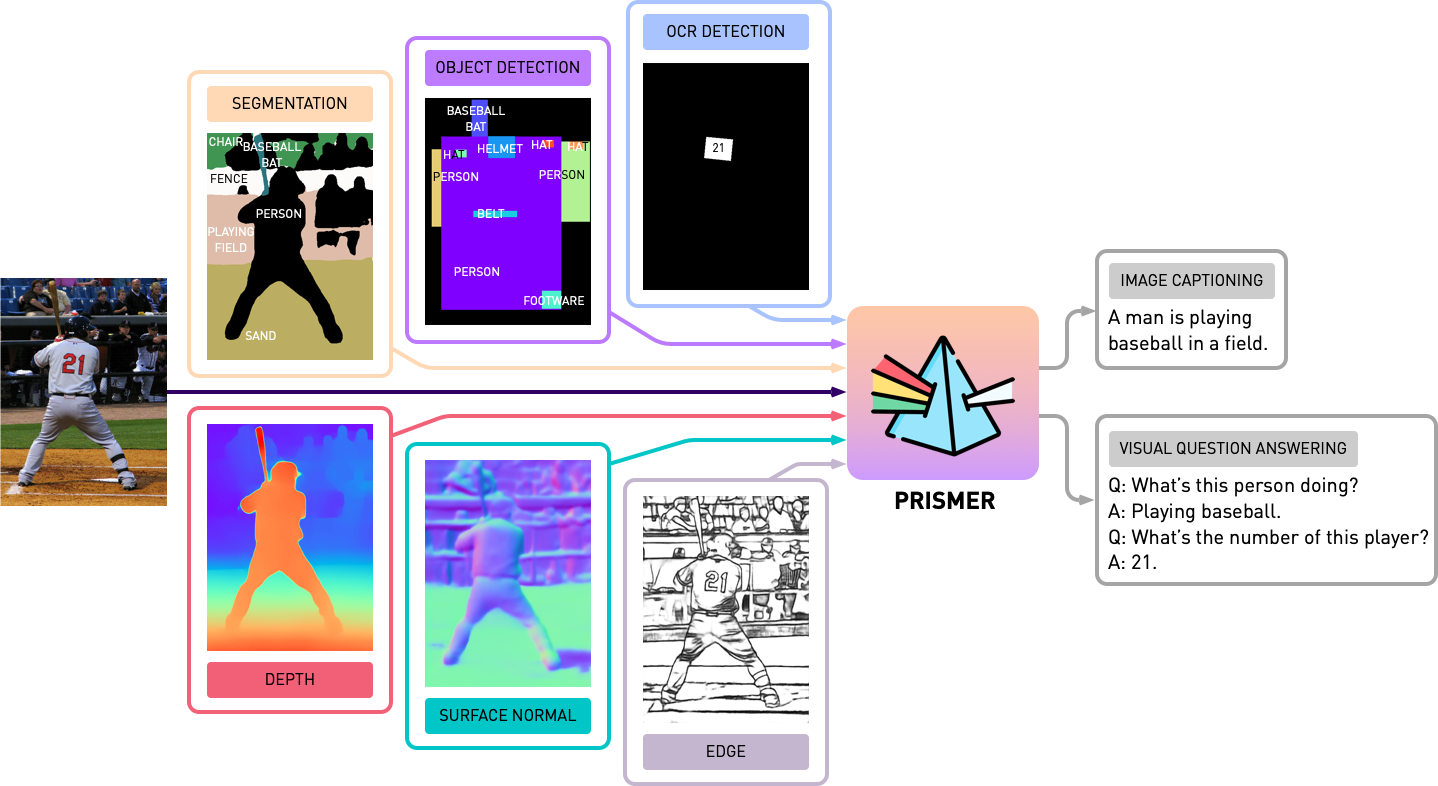
Prismer is a data-efficient vision-language model that leverages diverse pre-trained experts through its predicted multi-task signals. It can perform vision-language reasoning tasks such as image captioning and VQA.
Prismer Model Design
Prismer is an encoder-decoder transformer model that leverages a library of existing pre-trained experts. It consists of a vision encoder and an auto-regressive language decoder. The vision encoder takes an RGB image and its corresponding multi-task labels as input (e.g., depth, surface normal, segmentation labels, predicted from the frozen pre-trained experts), and outputs a sequence of RGB and multi-task features. The language decoder is then conditioned on these multi-task features via cross attention, and produces a sequence of text tokens.
Prismer is designed to fully leverage pre-trained experts whilst keeping the number of trainable parameters to a minimum. To do this, the majority of the network weights of the pre-trained experts are frozen to maintain the integrity of their learned knowledge and prevent catastrophic forgetting. To link the multi-task labels as well as the vision and language parts of Prismer, we insert two types of parameter-efficient trainable components:
-
Experts Resampler: The Experts Resampler learns a pre-defined number of latent input queries, to cross attend a flattened embedding concatenated from all multi-task features, as inspired by the Perceiver and the Flamingo Model. The Resampler then compresses the multi-task features into a much smaller number of tokens equal to the number of the learned latent queries, as a form of auxiliary knowledge distillation.
-
Adaptor: The Adaptor has an encoder-decoder design, which first down-projects the input features into a smaller dimension, applies a non-linearity, and then up-projects the features back to the original input dimension. With the residual connection, we initialise all adaptors with near-zero weights to approximate the identity function. Combined with a standard cross attention block in the language decoder, the model is able to smoothly transition from the domain-specific vision-only and language-only backbones to a vision-language model during pre-training with paired image-text data.
Prismer is a generative model, trained with a single objective, to predict the next text token autoregressively. As such, we re-formulate all vision-language reasoning tasks as a language modelling or prefix language modelling problem. For example, given the input image and with its multi-task tokens and a question as the prefix, the model generates the answer for the visual question answering task; given the input image and with its multi-task tokens, the model generates its caption for the image captioning task. Once we have a prefix prompt, we may either sample the output text in an autoregressive manner, as in an open-ended generative setting; or we may rank the log-likelihood from a fixed set of completions, as in a closed-ended generative setting.
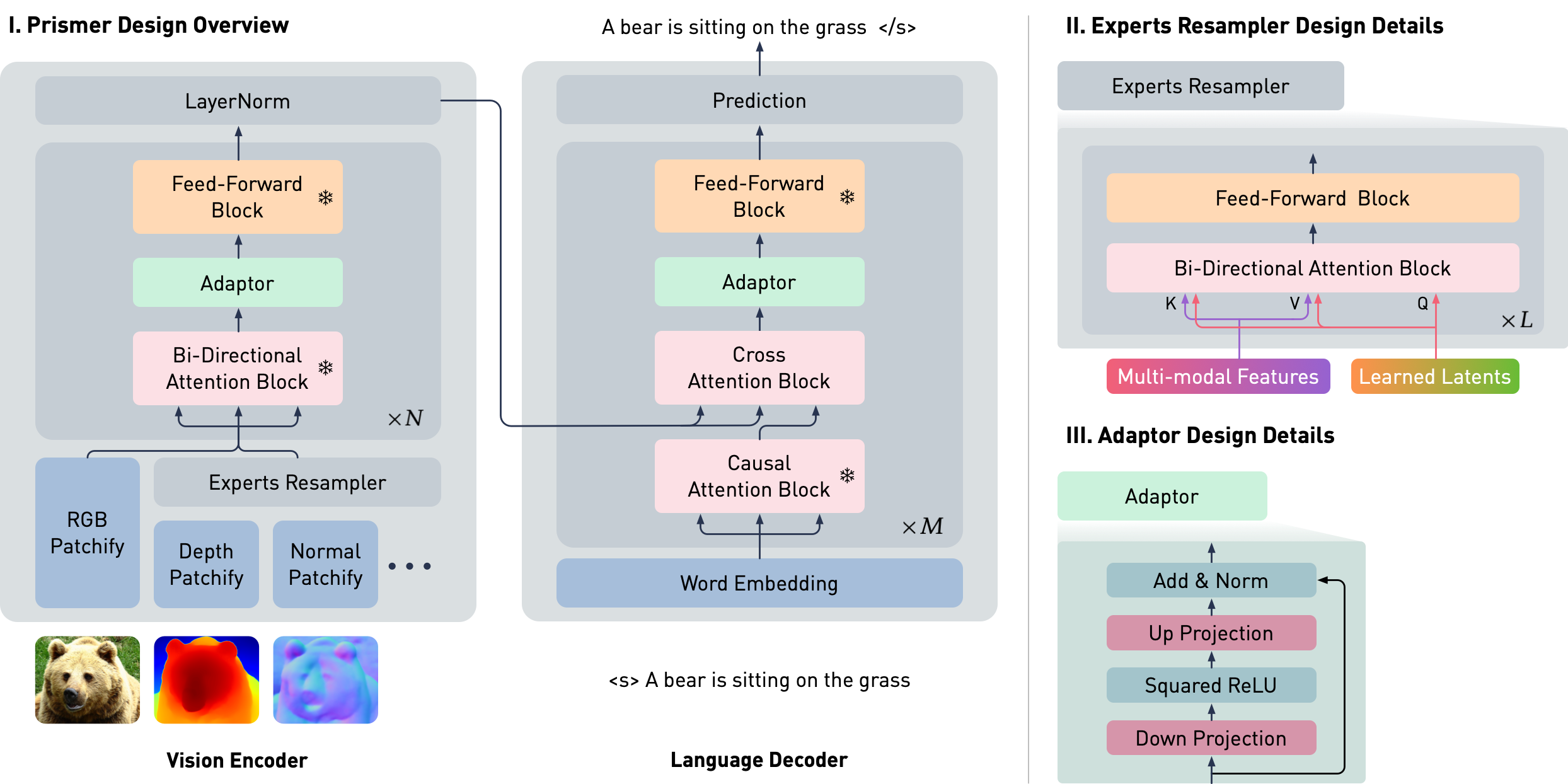
Prismer has two main trainable components: the Experts Resampler that converts variable multi-task signals to a fixed number of outputs, and the Adaptor that enhances the model's expressivity for vision-language reasoning. To ensure that the model takes advantage of the rich domain-specific knowledge encoded in the pre-trained experts, the majority of network weights are frozen during training, as represented by the snowflake icon.
Diverse, Task-specific Pre-trained Experts
In Prismer, we include two types of pre-trained experts:
-
Backbone Experts: The vision-only and language-only pre-trained models, which are responsible for encoding images and texts into a meaningful sequence of tokens. Both models are required to be based on the transformer architecture, so we can easily connect them with a few trainable components of similar designs. To preserve their rich domain-specific knowledge encoded in the network parameters, the majority of the weights are frozen during pre-training.
-
Task Experts: The models that can produce task-specific labels depending on their training datasets. In Prismer, we include up to 6 task experts all from the vision domain, encoding three low-level vision signals: depth, surface normals, and edge; and three high-level vision signals: object labels, segmentation labels, and text labels. These task experts are treated as black-box predictors, and their predicted labels are used as input for the Prismer model. As a result, all network weights of the task experts are frozen, and they can have any design.
Prismer Model Variants
In addition to the Prismer, we also introduce a model variant named PrismerZ, which solely relies on the power of strong backbone experts and is trained with zero task experts. PrismerZ has the same architectural design as the original Prismer but without the Experts Resampler. PrismerZ simplifies the data inference process as it only requires RGB images, making it more efficient and applicable to a wider range of applications. Prismer is less efficient in data inference due to the need for data processing on expert labels, but it will have a better performance.
Both Prismer and PrismerZ utilise Vision Transformer pre-trained by CLIP as the frozen vision encoder, and RoBERTa as the frozen language decoder. We experiment with two model sizes, BASE and LARGE. The BASE model is built on top o ViT-B/16 and RoBERTaBASE, and the LARGE model is built on top of ViT-L/14 and RoBERTaLARGE. In Prismer, we apply the Experts Resampler of the same design with roughly 50M parameters in both model sizes. The detailed architecture details are summarised in the following Table.
|
Resampler |
Vision Encoder |
Language Decoder |
Trainable Param. |
Total Param. |
|
Layers |
Width |
Backbone |
Layers |
Width |
Backbone |
Layers |
Width |
| PrismerBASE |
4 |
768 |
ViT-B/16 |
12 |
768 |
RoBERTaBASE |
12 |
768 |
160M |
980M |
| PrismerLARGE |
4 |
1024 |
ViT-L/14 |
24 |
768 |
RoBERTaLARGE |
24 |
1024 |
360M |
1.6B |
| PrismerZBASE |
- |
- |
ViT-B/16 |
12 |
768 |
RoBERTaBASE |
12 |
768 |
105M |
275M |
| PrismerZLARGE |
- |
- |
ViT-L/14 |
24 |
768 |
RoBERTaLARGE |
24 |
1024 |
270M |
870M |
We report the backbone we choose for each architecture size, along with its corresponding number of layers and width. We also report the number of trainable parameters and total parameters for each architecture. We count the total parameters required for data inference, which include the additional 6 task experts with a combined parameter size of 654M parameters in our Prismer model.
Experiments
Fine-tuned Performance on NoCaps and VQAv2
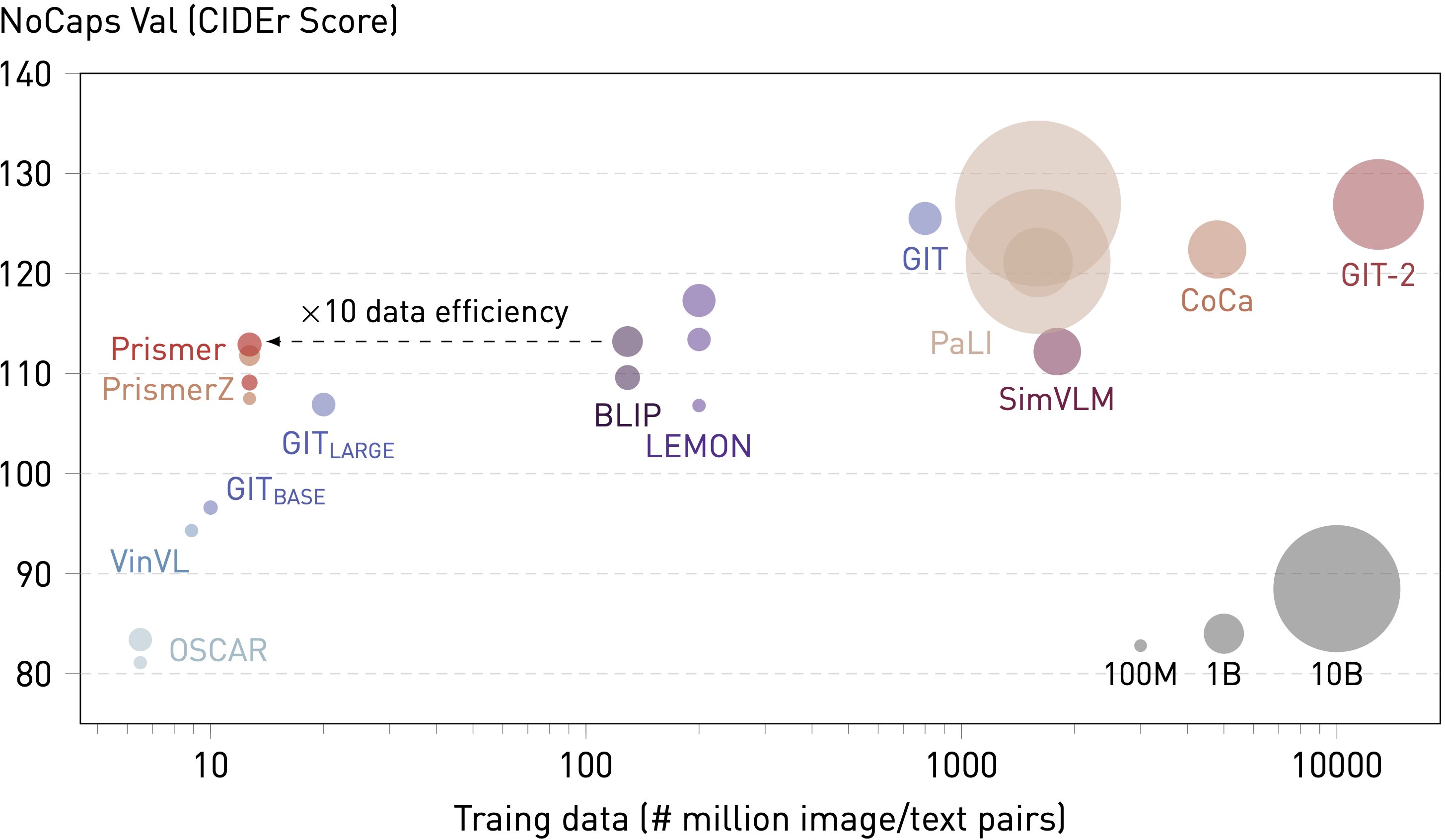
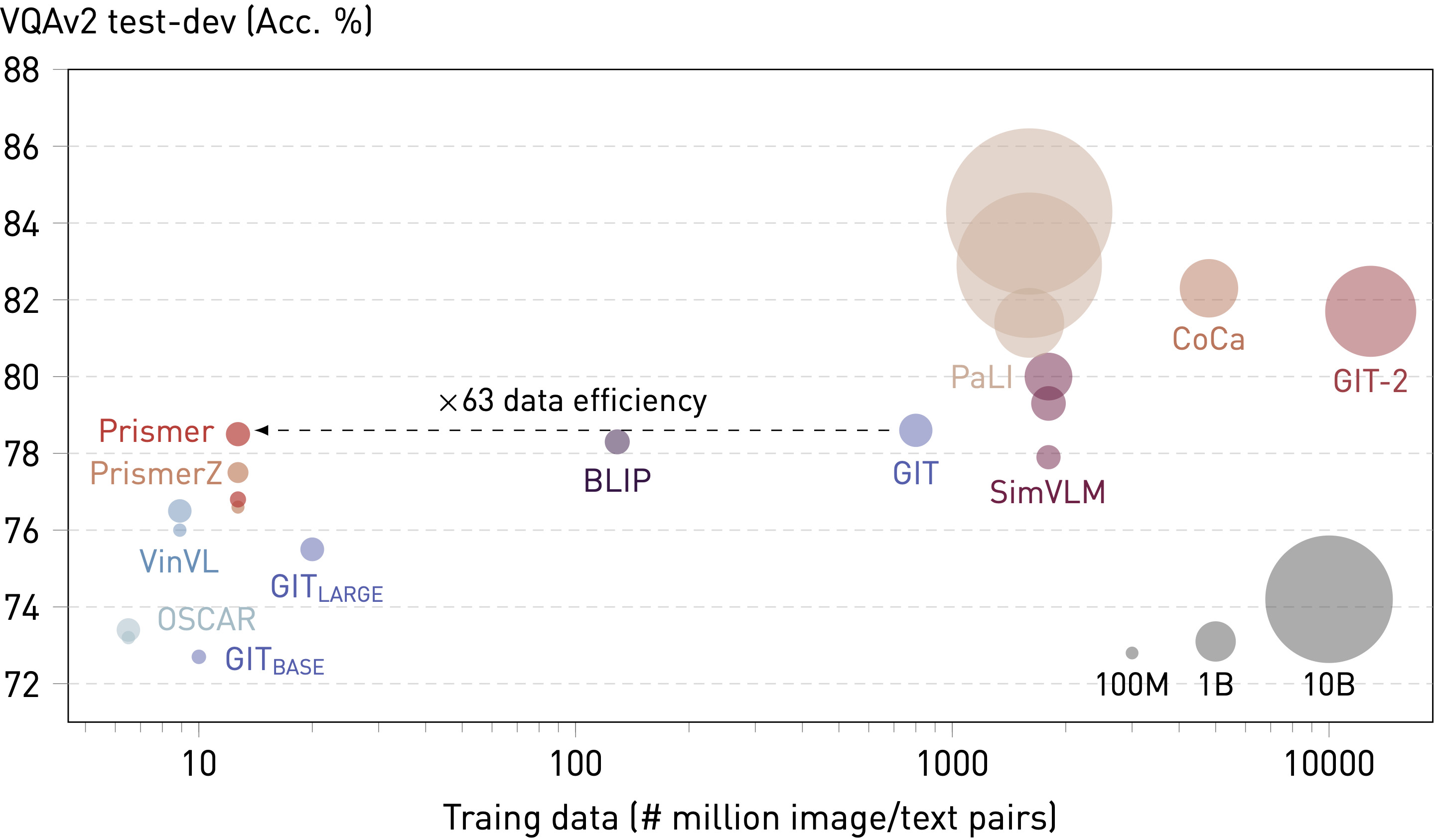
We show that both Prismer and PrismerZ can achieve superior performance considering their model sizes, which suggests that the strong backbone experts are primarily responsible for good generalisation. However, the task experts provide an additional boost in performance, particularly in image captioning tasks and in the LARGE model variant. Prismer has achieved comparable image captioning performance to BLIP and LEMON, despite being trained on 10 and 20 times less data, respectively. Additionally, the Prismer has achieved VQAv2 accuracy comparable to GIT, despite being trained on 60 times less data. Whilst we acknowledge a noticeable performance gap between Prismer and the current state-of-the-art VLMs (such as CoCa, GIT-2 and PaLI), these models require substantially higher training costs and access to large-scale private training data.
Both Prismer and PrismerZ have achieved superior fine-tuned performance in NoCaps and VQAv2 dataset compared to other VLMs with similar model sizes. Prismer can achieve competitive performance on par with VLMs that are trained with orders of magnitude more data. The size of a bubble represents the number of trainable network parameters during multi-modal pre-training.
Zero-shot Performance on COCO Caption and NoCaps
Our generative pre-training approach allows for zero-shot generalisation, where the models can be directly applied to image captioning tasks without additional fine-tuning. In the following table, we show that Prismer achieves significantly better performance to SimVLM on the NoCaps dataset, whilst using 140 times less training data. Additionally, we notice that the zero-shot performance of Prismer models even surpasses the fine-tuned performance of certain VLMs such as OSCAR and VinVL, as shown in the previous section.
|
COCO Caption |
|
B@4 |
M |
C |
S |
| ZeroCap |
2.6 |
11.5 |
14.6 |
5.5 |
| MetaLM |
24.5 |
22.5 |
82.2 |
15.7 |
| VLKD |
25.8 |
23.1 |
85.1 |
16.9 |
| Flamingo |
- |
- |
84.3 |
- |
| CapDec |
26.4 |
25.1 |
91.8 |
- |
| Prismer |
39.5 |
30.4 |
129.7 |
23.8 |
|
NoCaps |
|
C |
S |
| FewVLM |
47.7 |
9.1 |
| MetaLM |
58.7 |
8.6 |
| VLKD |
63.6 |
12.8 |
| SimVLMLARGE |
96.6 |
- |
| SimVLMHUGE |
101.4 |
- |
| Prismer |
107.9 |
14.8 |
Prismer achieves state-of-the-art zero-shot image-captioning results on COCO Caption (Karpathy test) and NoCaps (validation set), outperforms SimVLM by a large margin, despite being trained on 140 times less data.
We present a list of example captions generated by Prismer, along with their corresponding RGB images and task expert predictions as shown below. The results show that both PrismerBASE and PrismerLARGE are capable of generating captions that are semantically coherent and aligned with the visual content of the images. Notably, PrismerLARGE generates captions of higher quality compared to PrismerBASE, exhibiting a deep understanding of fine-grained object semantics such as brand recognition (e.g. Mercedes, CK One), and cultural concepts (e.g. vintage drawing, tango), indistinguishable to human-written captions.
Interestingly, we can easily notice that some of the expert predictions are either incorrect or not useful for image captioning. This observation motivates us to design Prismer not to overly rely on expert labels, and only consider them as auxiliary signals.
Input Image
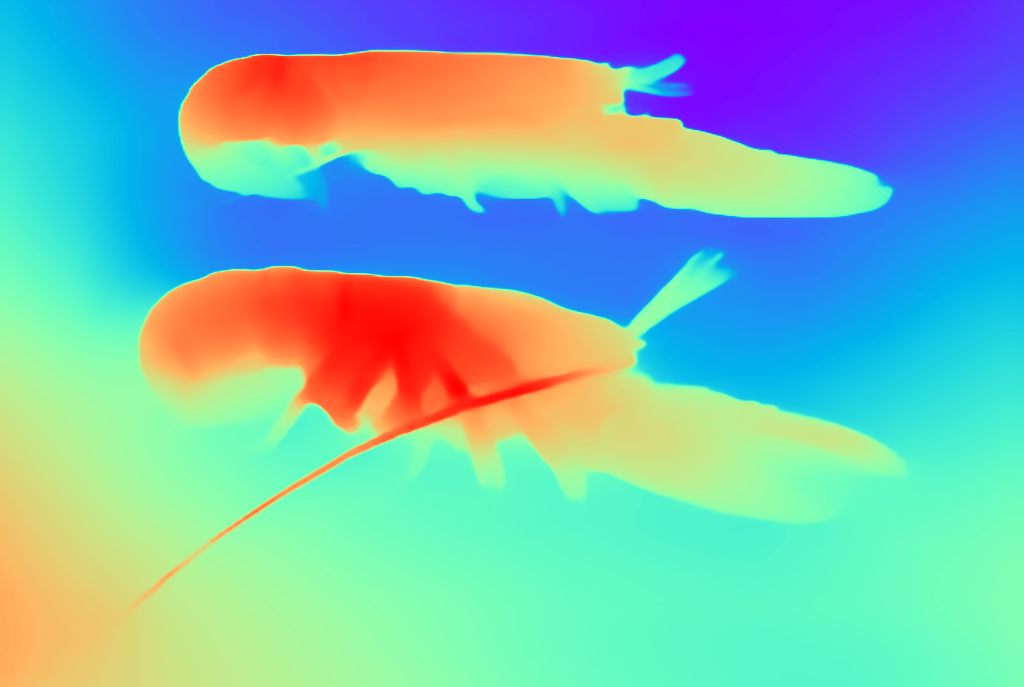
Depth
Surface Normals
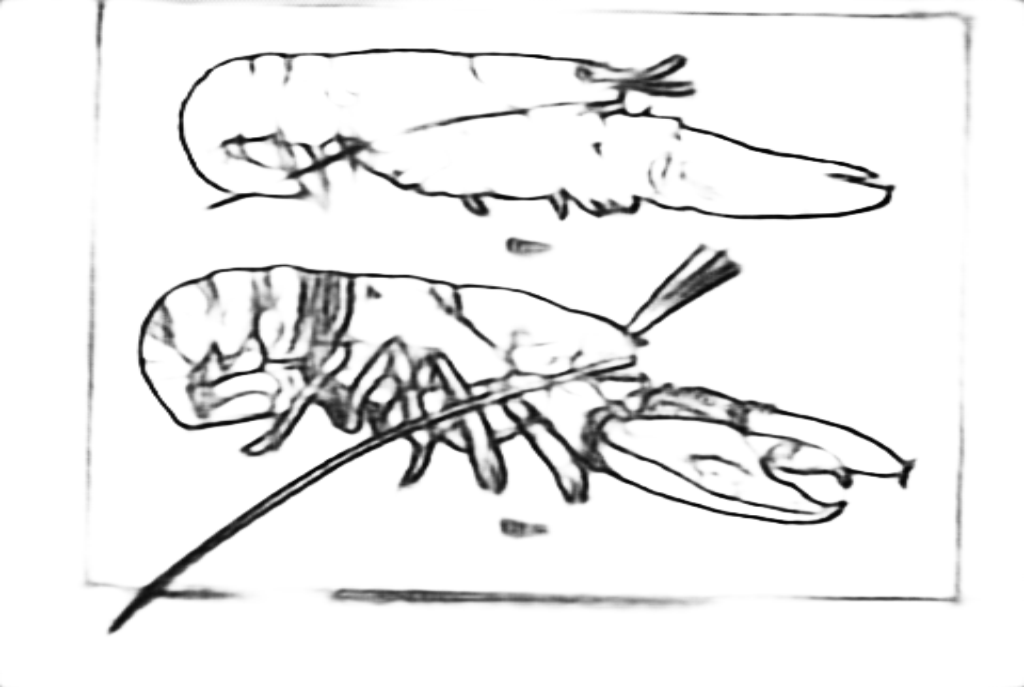
Edge
Object Detection
Segmentation
OCR Detection




PrismerBASE Zero-shot Caption:
A bottle of alcohol sitting next to a computer keyboard.
PrismerLARGE Zero-shot Caption:
A bottle of ck one next to a computer keyboard.
1. A clear bottle of CK cologne is full of liquid.
2. A bottle of cologne is sitting on a keyboard.
3. A bottle of cologne sits next to a computer keyboard.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection






PrismerBASE Zero-shot Caption:
An old photo of a little girl standing on a step.
PrismerLARGE Zero-shot Caption:
An old black and white photo of a baby standing in front of a house.
1. A young child stands in front of a house.
2. A little boy is standing in his diaper with a white shirt on.
3. A child is wearing a light-colored shirt during the daytime.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection



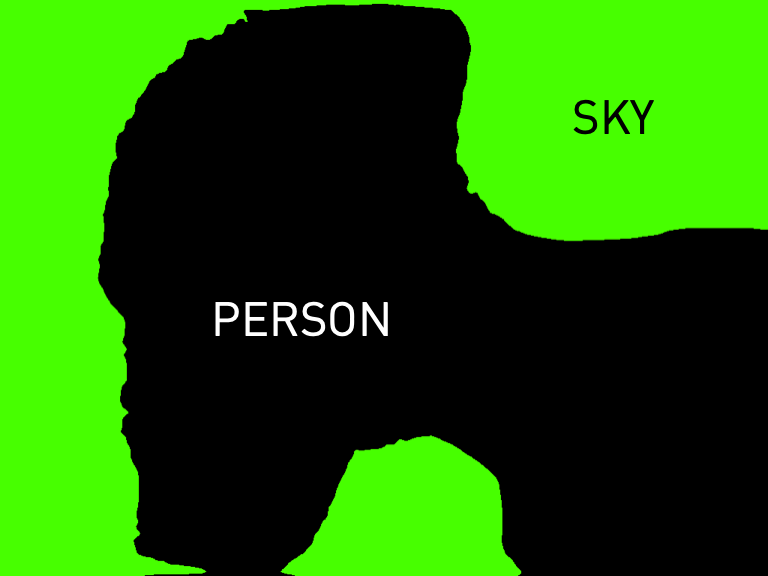

PrismerBASE Zero-shot Caption:
The woman is wearing a black dress.
PrismerLARGE Zero-shot Caption:
A mannequin dressed in a black dress with feathers on her head.
1. A statue has a large purple headdress on it.
2. A woman decorated in fashioned clothing and relics.
3. A mannequin wearing a blue wig and elaborate headdress.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection

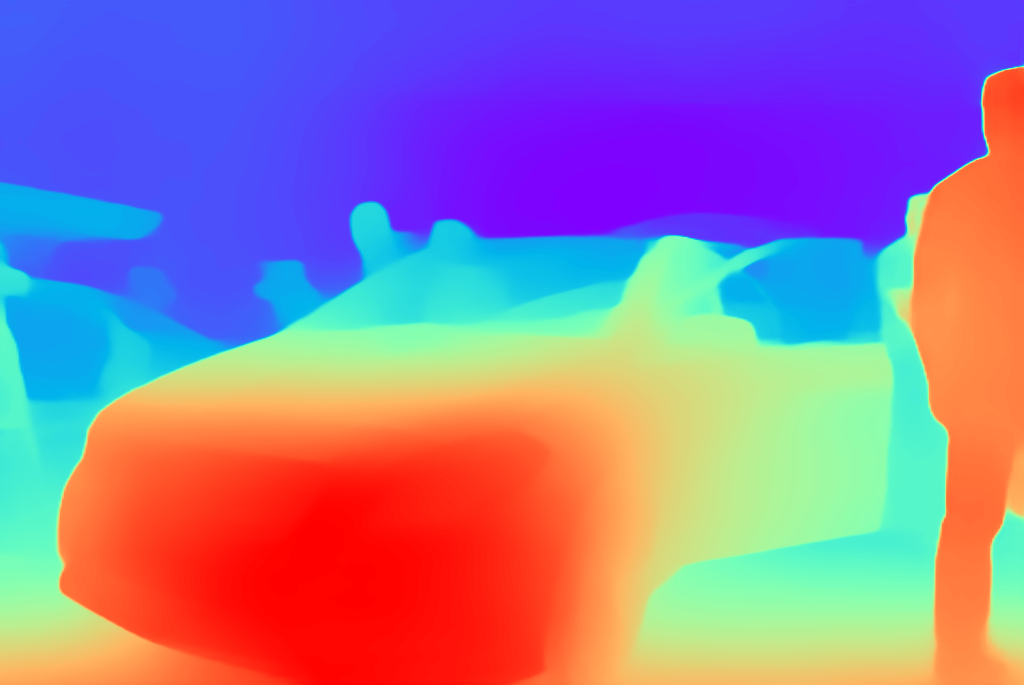


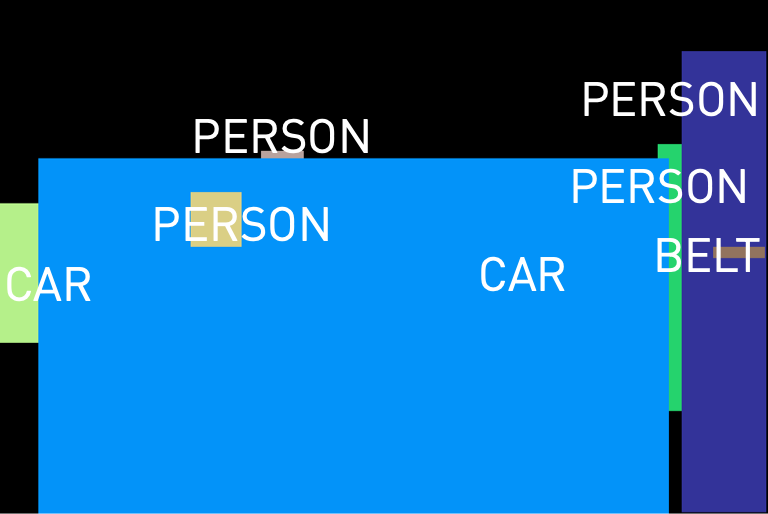
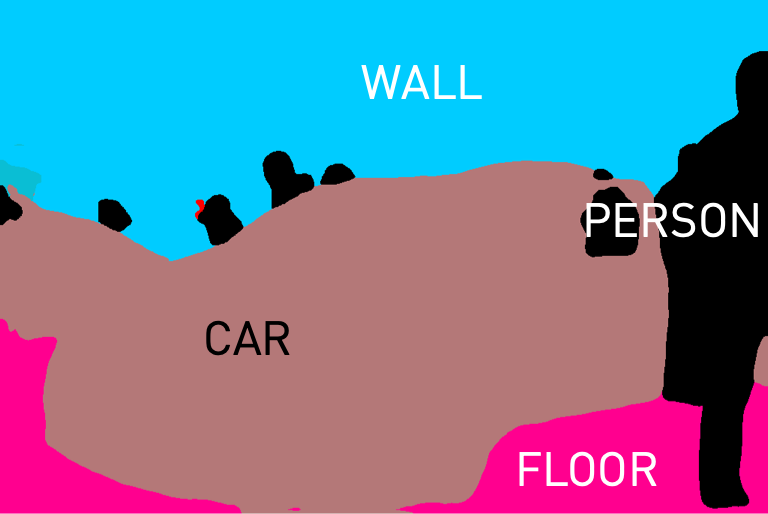

PrismerBASE Zero-shot Caption:
A white car on display at a car show.
PrismerLARGE Zero-shot Caption:
A white mercedes car on display at an auto show.
1. A new white car with the door open is in a showroom full of people.
2. A shiny white mercedes car is on display.
3. A white car with an opened door and someone sitting in it with the legs outside.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection





PrismerBASE Zero-shot Caption:
Pineapples on a plate.
PrismerLARGE Zero-shot Caption:
Pineapple upside down cake on a blue and white plate.
1. Ham with pineapple rings and maraschino cherries stuck with toothpicks.
2. A cake has several slices of pineapple and cheries in them.
3. A lot of pineapple that is all on a large ham.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection




PrismerBASE Zero-shot Caption:
A couple of people that are standing in the dirt.
PrismerLARGE Zero-shot Caption:
A couple dancing tango in front of a crowd.
1. A man and woman is dancing as a crowd watches them in the distance.
2. A woman in a red dress dancing with a bald man wearing black.
3. A man and woman dancing together outdoors at a festival.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection




PrismerBASE Zero-shot Caption:
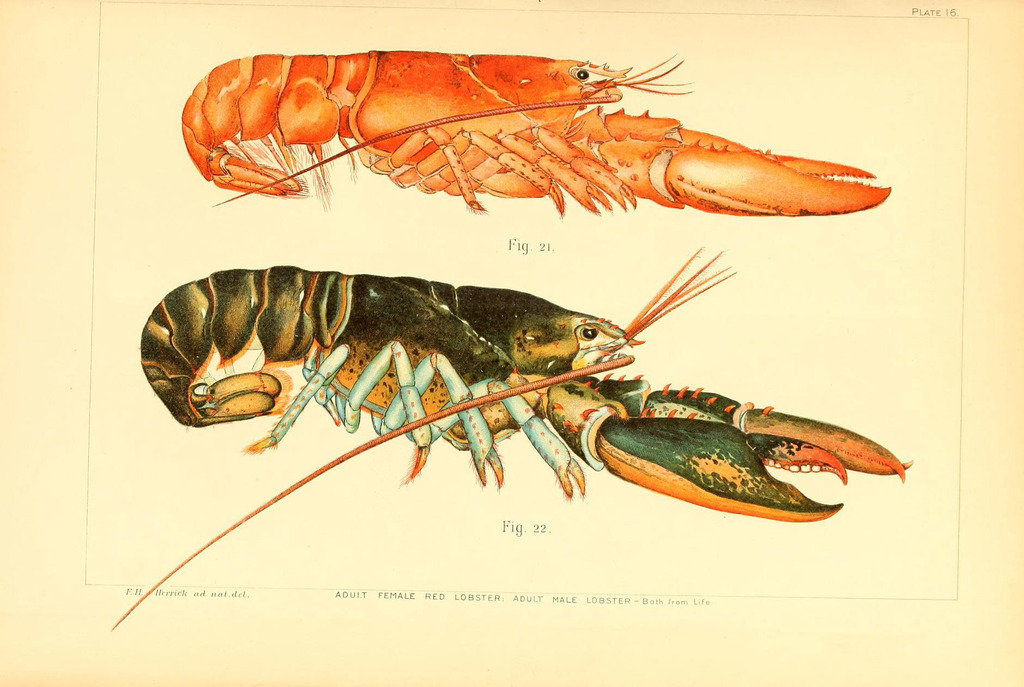
A vintage illustration of lobsters from the 19th century.
PrismerLARGE Zero-shot Caption:
Colored drawing of two lobsters on pink paper.
1. A diagram of a red lobster that is on a piece of paper.
2. Two illustrations of lobster colors are shown as Fig. 21 and Fig. 22.
3. Colored drawing of two lobsters on pink paper.
Input Image
Depth
Surface Normals
Edge
Object Detection
Segmentation
OCR Detection






PrismerBASE Zero-shot Caption:
Man wearing a blue and purple jacket.
PrismerLARGE Zero-shot Caption:
A man wearing a helmet and goggles with parachutes in the background.
1. Man in skydiving gear giving two thumbs up with skydivers in the sky behind him.
2. Person giving double thumbs up sign while others are parachuting in the background.
3. A man in a leather helment and goggles skydiving.
Few-shot Performance on ImageNet Classification
Finally, we fine-tune and evaluate Prismer on ImageNet dataset in a few-shot setting. Following the approach outlined in CLIP, we convert the classification task into a language modelling problem by mapping each unique category to a template caption: "A photo of a [CLASS NAME]". Unlike Flamingo that performs few-shot classification via in-context examples without gradient updates, we perform few-shot classification via lightweight fine-tuning following GIT. This is more similar to the standard linear probe setting, by considering the entire language decoder as an image classifier. Accordingly, we also compare with the few-shot linear probe performance of Prismer's original vision backbones ViT-B/16 and ViT-L/14.
From the results shown in the figure right, we observe that Prismer underperforms GIT and Flamingo, which both have stronger vision backbones and are pre-trained on significantly more data. However, Prismer still outperforms its original vision backbones ViT-B and ViT-L by a large margin, especially in a very few-shot setting. This suggests that Prismer's generalisation abilities are enhanced by the multi-modal training data and expert labels, and its performance can likely be improved further by using an even stronger vision backbone.
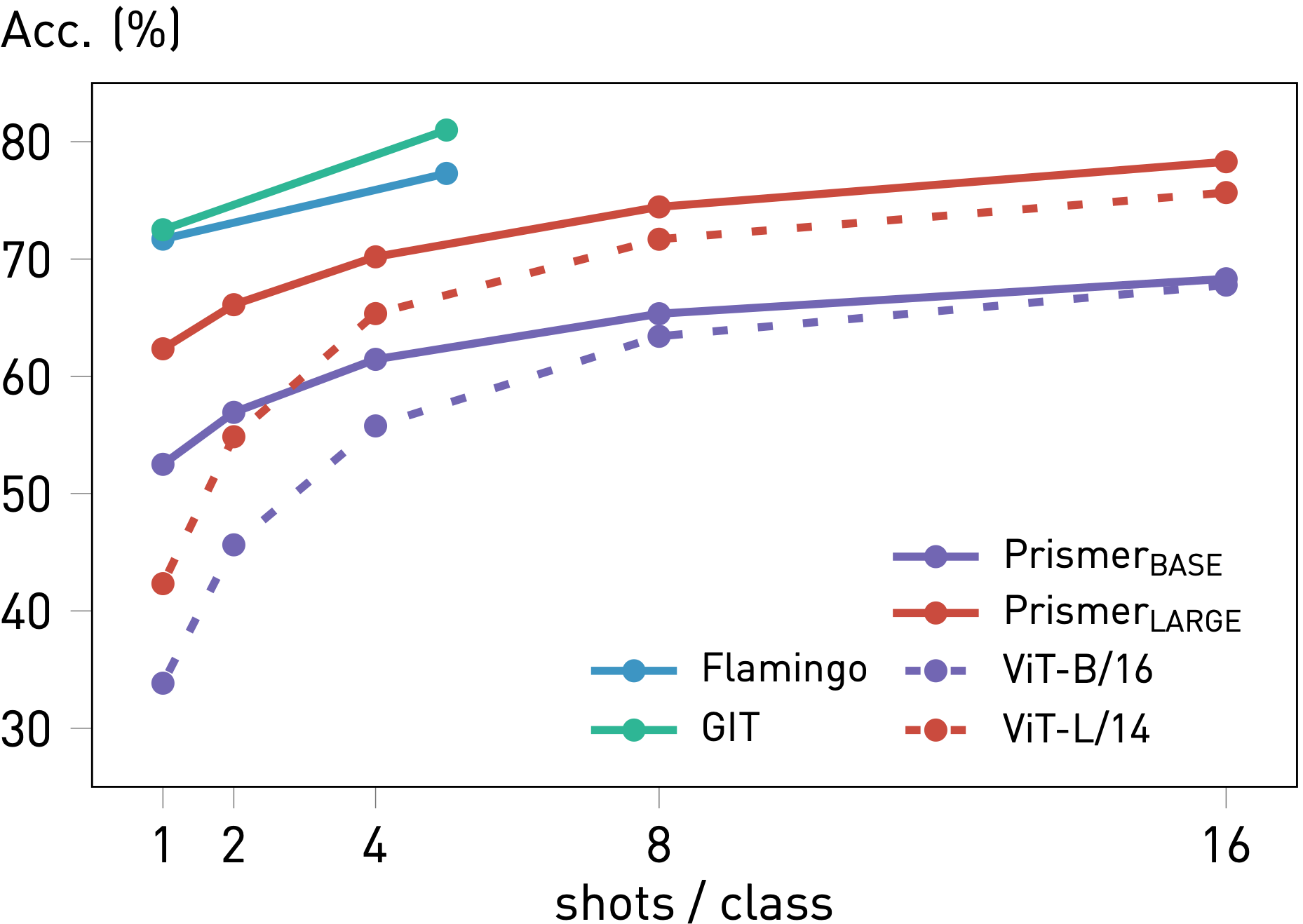
Prismer significantly improves few-shot performance compared to its corresponding vision backbone. However, Prismer still underperforms GIT and Flamingo which are trained on significantly more data.
Intriguing Properties of Prismer
We conduct experiments to probe Prismer carefully and discover some interesting abilities. All experiments are evaluated on the VQAv2 test-dev split, with a reduced training setting.
with More Experts
with Better Experts
with Noisy Expert
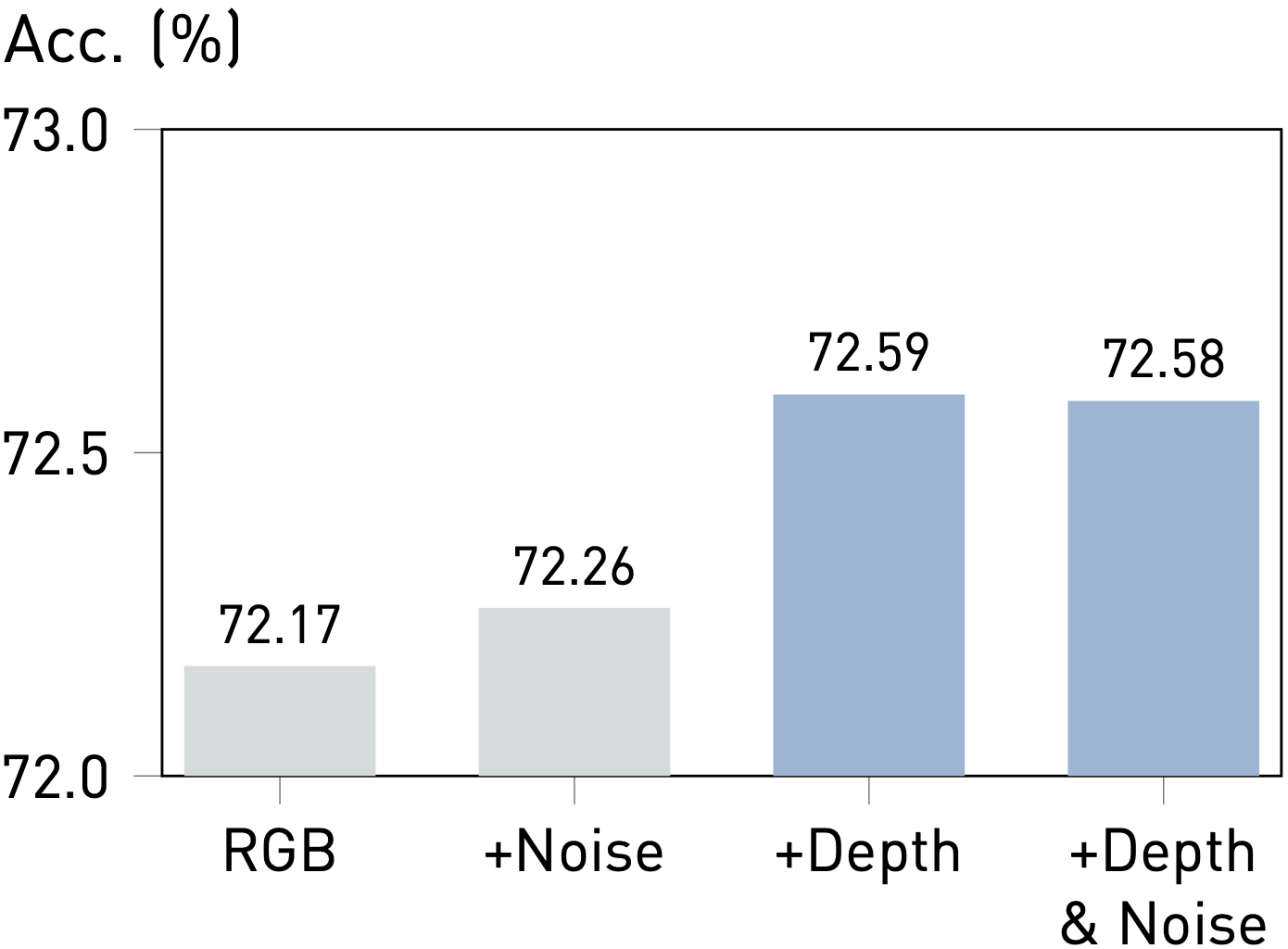
Prismer has shown that its performance improves with an increase in the number and quality of task experts. Additionally, Prismer also demonstrates its strong robustness to noisy experts, making it a practical and effective learning technique.
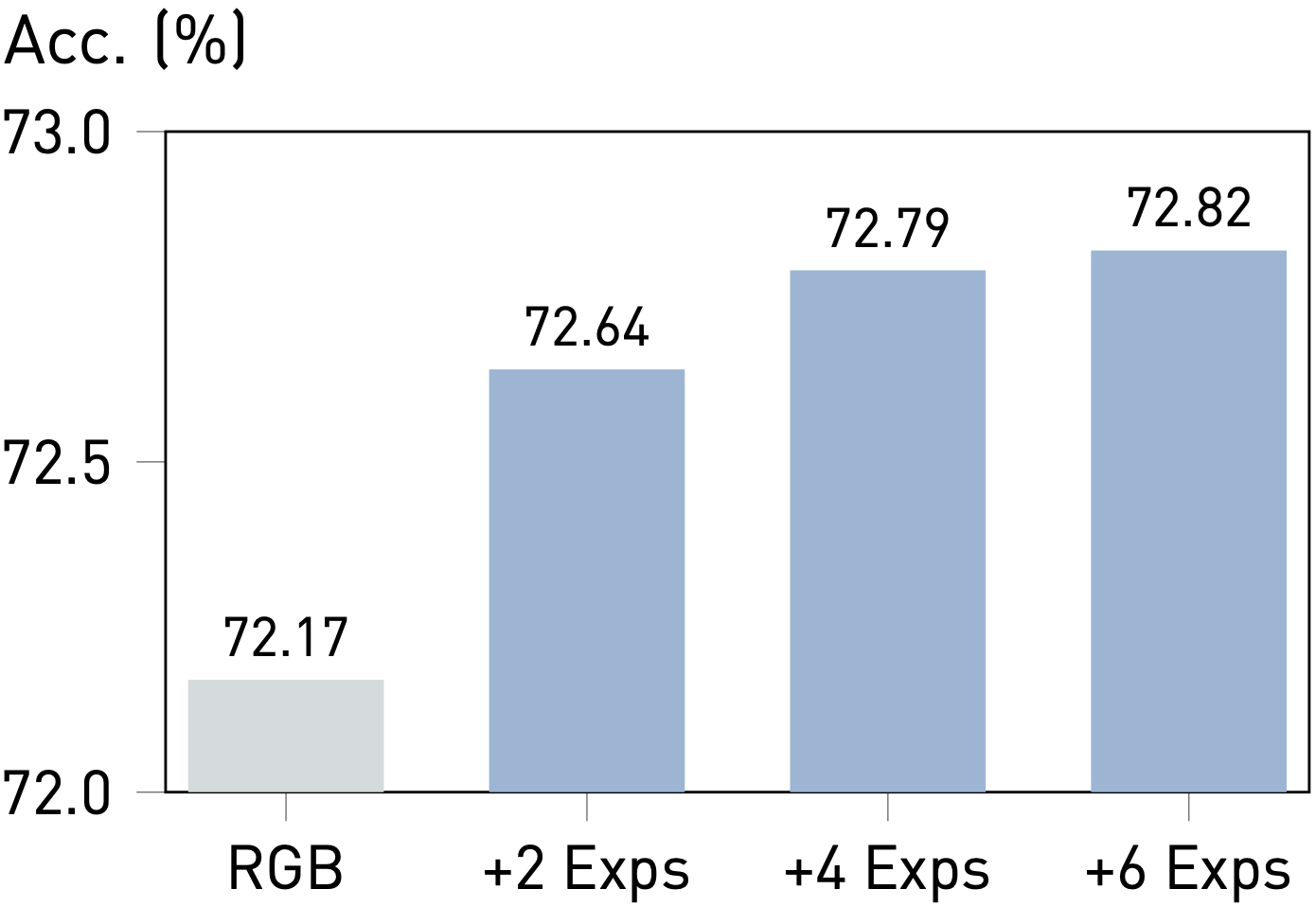
Observation #1: More Experts, Better Performance.
We observe that the performance of Prismer improves with the addition of more task experts. This is because more experts provide a greater diversity of domain knowledge to the model. However, we also note that the performance of the model eventually plateaus, which suggests that additional task experts do not provide any extra gains beyond a certain number.
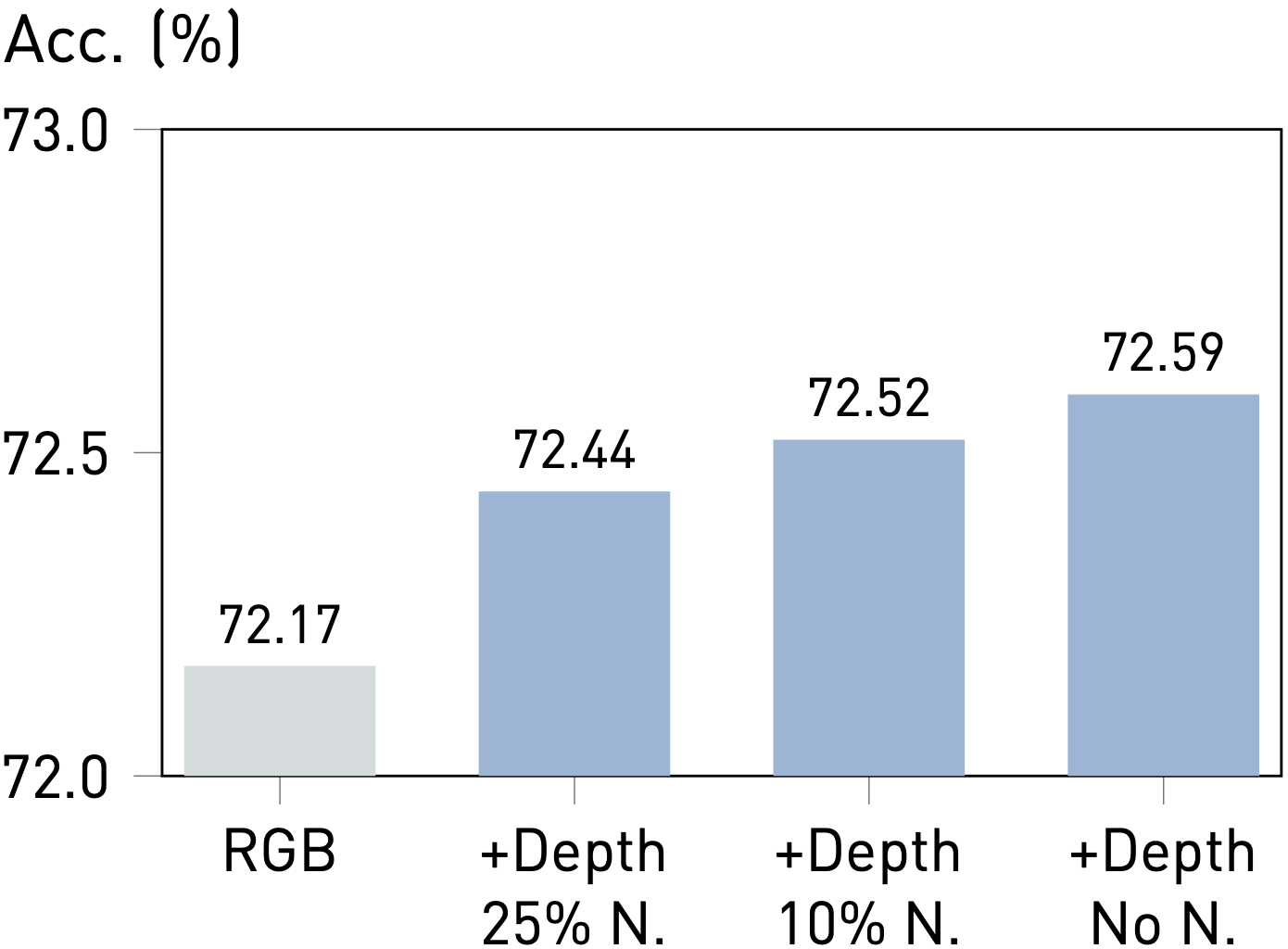
Observation #2: Better Experts, Better Performance.
To evaluate the impact of expert quality on Prismer's performance, we construct a corrupted depth expert by replacing a certain number of predicted depth labels with random noise sampled from a Uniform Distribution. Prismer's performance improves as the quality of the depth expert improves. This is intuitive as better experts provide more accurate domain knowledge, allowing the model to perceive more accurately.
Observation #3: Robustness to Noisy Experts.
Our results also demonstrate that Prismer maintains performance even when including experts that predict noise. Interestingly, adding noise can even result in a non-trivial improvement compared to training on RGB images alone, which can be considered as a form of implicit regularisation. This property allows the model to safely include many experts without degrading the performance, even when the expert is not necessarily informative. Therefore, Prismer presents a more effective learning strategy than the standard multi-task or auxiliary learning methods, which either require exploring task relationships or designing more advanced optimisation procedures.
Conclusions, Limitations and Discussions
In this paper, we have introduced Prismer, a vision-language generative model designed for reasoning tasks. Prismer is parameter-efficient and utilises a small number of trainable components to connect an ensemble of diverse, pre-trained experts. By leveraging these experts, Prismer achieves competitive performance in image captioning, VQA, and image classification benchmarks, comparable to models trained on up to two orders of magnitude more data.
For full transparency, we now discuss some limitations of Prismer during our implementation and explore potential future directions for this work.
Multi-modal In-context Learning: Zero-shot in-context generalisation is an emergent property that only exists in very large language models. In this work, we build Prismer on top of a small-scale language model with the main focus on parameter-efficient learning. Therefore, it does not have the ability to perform few-shot in-context prompting by design.
Zero-shot Adaptation on New Experts: We experiment with inference on a pre-trained Prismer with a different segmentation expert pre-trained on a different dataset. Although we apply the same language model to encode semantic labels, Prismer shows limited adaptability to a different expert with a different set of semantic information, which leads to a notable performance drop.
Free-form Inference on Partial Experts: Similarly, we discover that Prismer entangles its multi-task features from all experts we include during pre-training. Therefore, only having a partial number of experts during inference will lead to a notable performance drop. We attempt to use a different training objective such as masked auto-encoding, to design Prismer to reason on an arbitrary number of experts, but it eventually leads to a degraded fine-tuned performance.
Representation of Expert Knowledge: In our current design of Prismer, we convert all expert labels into an image-like 3-dimensional tensor via task-specific post-processing for simplicity. There are other efficient methods to represent expert knowledge, such as converting object detection into a sequence of text tokens. This may lead to stronger reasoning performance and a more stable training landscape in future works.
Citation
If you found this work is useful in your own research, please considering citing the following.
@article{liu2024prismer,
title={Prismer: A Vision-Language Model with Multi-Task Experts},
author={Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima},
journal={Transactions on Machine Learning Research},
year={2024}
}

Prismer is a data-efficient vision-language model that leverages diverse pre-trained experts through its predicted multi-task signals. It can perform vision-language reasoning tasks such as image captioning and VQA.
The model name "Prismer" draws from the analogy to an optical prism which breaks a white light into a spectrum of colours, and here we break down a single reasoning task into diverse domain-specific reasoning.