


























































We present ReCo, a contrastive learning framework designed at a regional level to assist learning in semantic segmentation. ReCo performs semi-supervised or supervised pixel-level contrastive learning on a sparse set of hard negative pixels, with minimal additional memory footprint. The strongest effect is in semi-supervised learning with very few labels. With ReCo, we can achieve high-quality semantic segmentation models, whilst requiring only 5 examples of each semantic class.
ICLR 2022
ReCo is a pixel-level contrastive framework — a new loss function which helps semantic segmentation not only to learn from local context (neighbouring pixels), but also from global context across the entire dataset (semantic class relationships). ReCo can perform supervised or semi-supervised contrastive learning on a pixel-level dense representation. For each semantic class in a training mini-batch, ReCo samples a set of pixel-level representations (queries), and encourages them to be close to the class mean averaged across all representations in this class (positive keys), and simultaneously pushes them away from representations sampled from other classes (negative keys).
For pixel-level contrastive learning with high-resolution images, it is impractical to sample all pixels. In ReCo, we actively sample a sparse set of queries and keys, consisting of less than 5% of all available pixels. We sample negative keys from a learned distribution based on the relative distance between the mean representation of each negative key class and the query class. This distribution can be interpreted as a pairwise semantic class relationship, dynamically updated during training. We sample queries for those corresponding pixels having a low prediction confidence. Active sampling helps ReCo to rapidly focus on the most confusing pixels for each semantic class, and requires minimal additional memory.
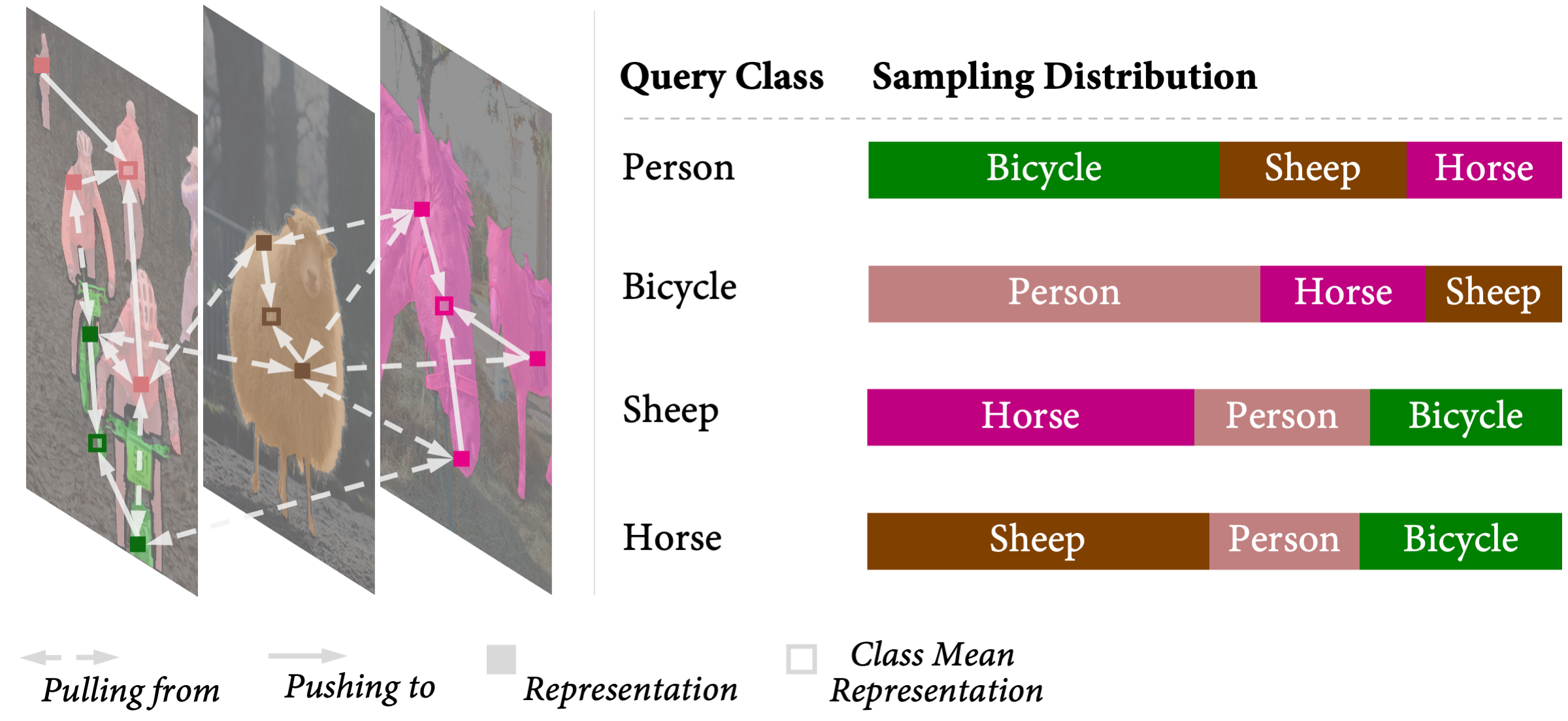
ReCo pushes representations within a class closer to the class mean representation, whilst simultaneously pushing these representations away from negative representations sampled in different classes. The sampling distribution from negative classes is adaptive to each query class. For example, due to the strong relation between bicycle and person class, ReCo will sample more representations in bicycle class, when learning person class, compared to other classes.
ReCo can easily be added to modern supervised and semi-supervised segmentation methods without changing the training pipeline, with no additional cost at inference time. To incorporate ReCo, we simply add an additional representation head on top of the feature encoder of a segmentation network, and apply the ReCo loss to this representation using the active sampling strategy. Following prior contrastive learning methods: MoCo, we only compute gradients on queries, for better training stabilisation.
In the supervised segmentation setting, where all training data have ground-truth annotations, we apply the ReCo loss on dense representations corresponding to all valid pixels. The overall training loss is then the linear combination of the supervised cross-entropy loss and the ReCo loss.
In the semi-supervised segmentation setting, where only part of the training data has ground-truth annotations, we apply the Mean Teacher framework. Instead of using the original segmentation network (which we call the student model), we use a copy of the student network (which we call the teacher model) to generate pseudo-labels from unlabelled images. This teacher model's network parameter is a moving average of the previous state of the network parameters from the student model, can be treated as a temporal ensemble of student models across training time, resulting in more stable predictions for unlabelled images. The student model is then used to train on the augmented unlabelled images, with pseudo-labels as the ground-truths.
For all pixels with defined ground-truth labels, we apply the ReCo loss similarly to the supervised segmentation setting. For all pixels without such labels, we only sample pixels whose predicted pseudo-label confidence is greater than a user-defined threshold. This avoids sampling pixels which are likely to have incorrect pseudo-labels. We apply the ReCo loss to a combined set of pixels from both labelled and unlabelled images. The overall training loss for semi-supervised segmentation is then the linear combination of supervised cross-entropy loss (on ground-truth labels), unsupervised cross-entropy loss (on pseudo-labels) and ReCo loss.
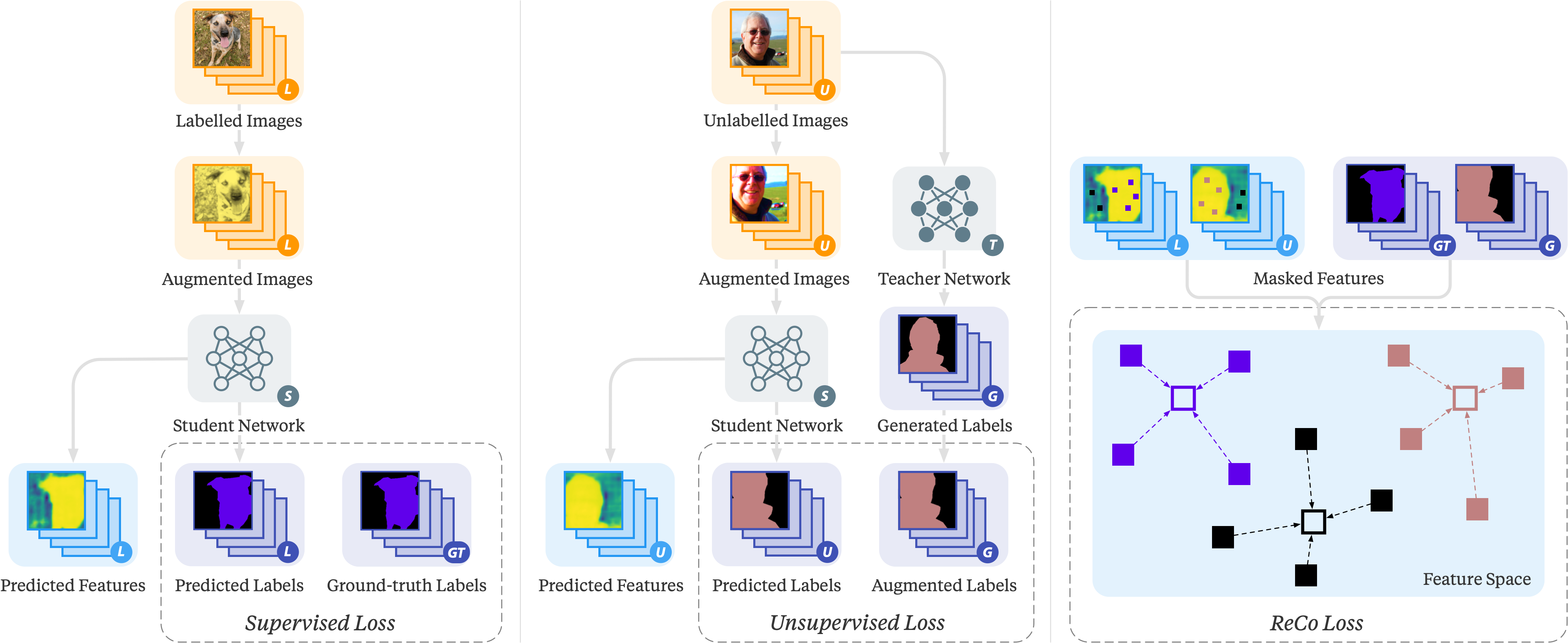
Visualisation of the ReCo framework applied to semi-supervised segmentation and trained with three losses. A supervised loss is computed based on labelled data with ground-truth annotations. An unsupervised loss is computed for unlabelled data with generated pseudo-labels. And finally a ReCo loss is computed based on pixel-level dense representation predicted from both labelled and unlabelled images.
ReCo enables a high-accuracy segmentation model to be trained with very few human annotations. To accurately evaluate ReCo'a generalisation ability, we propose two modes of semi-supervised segmentation tasks aiming at different applications.
Partial Dataset Full Labels: A small subset of the images is trained with complete ground-truth labels, whilst the remaining training images are unlabelled. When creating the labelled dataset, we sample labelled images based on two conditions: i) Each sampled image must contain a distinct number of classes greater than a manually-defined threshold. ii) Each sampled image must contain one of the least sampled classes in the previously sampled images. These two conditions ensure that the class distribution is more consistent across different random seeds, and ensures that all classes are represented. We are therefore able to evaluate the performance of semi-supervised methods with a very small number of labelled images without worrying about some rare classes being completely absent.
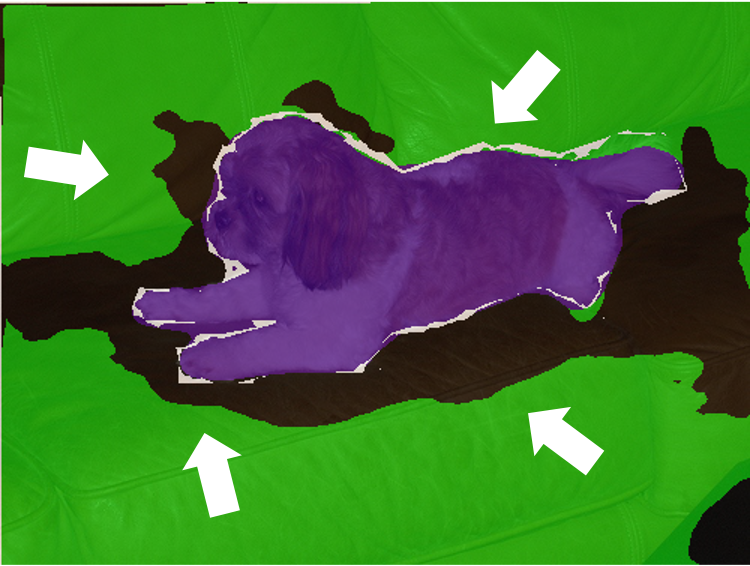
Partial Labels Full Dataset: All images are trained with partial labels, but only a few percentage of labels are provided for each class in each training image. We create the dataset by first randomly sampling a pixel for each class, and then continuously apply a [5 × 5] square kernel for dilation until we meet the percentage criteria.
1 Pixel
1% Labels
5% Labels
25% Labels




Background
Boat
Dog
Person
Undefined
Example of training labels for Pascal VOC dataset in Partial Labels Full Dataset setting. (1 Pixel is zoomed 5 times for better visualisation.)
The Partial Dataset Full Label evaluates learning to generalise semantic classes given few examples with perfect boundary information. The Partial Label Full Dataset evaluates learning semantic class completion given many examples with no or minimal boundary information.
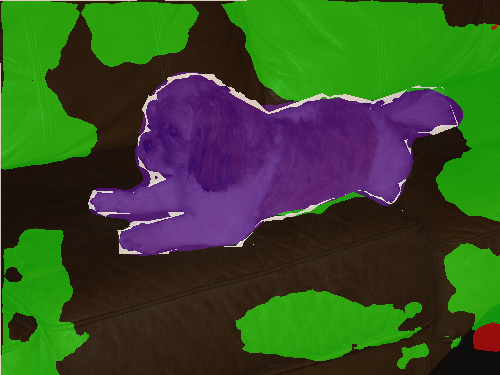
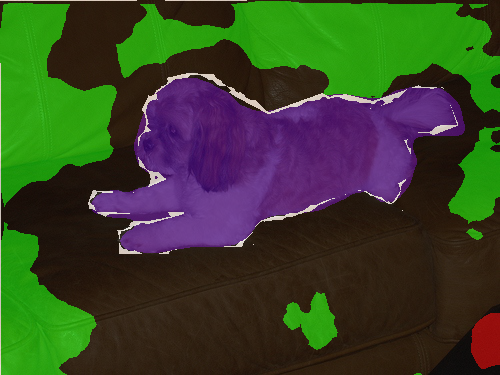
First, we compared our results to baselines in a full label setting. For semi-supervised learning, we applied ReCo on top of ClassMix, which consistently outperformed other semi-supervised baselines. We presented qualitative results from the semi-supervised setup with fewest labels: 60 labelled Pascal VOC, 20 labelled CityScapes, and 50 labelled SUN RGB-D datasets. The number of labelled images are chosen such that the least appeared classes in each dataset have appeared in 5 images. Please refer to the original paper for the quantitative evaluation.
In the partial label setting, we evaluated on the CityScapes and Pascal VOC datasets. Again, we see ReCo can improve performance in all cases both quantitatively and qualitatively. However, we observe less relative performance improvement (particularly in Supervised baseline) than in the full label setting; a very low level of ground-truth annotations could confuse ReCo to provide inaccurate supervision. Learning semantics with partial labels with minimal boundary information remains an open research question and still has huge scope for improvements.
Visualisation of trained with per class in each image.
Ground Truth
Supervised
ClassMix
ReCo + ClassMix

















Background
Aeroplane
Bicycle
Bird
Boat
Bottle
Bus
Car
Cat
Chair
Cow
Table
Dog
Horse
Motorbike
Person
Plant
Sheep
Sofa
Train
Monitor
Undefined
As in the full label setting, we see ReCo can generate smoother and more accurate boundary predictions in Pascal dataset.
In this section, we visualise the pair-wise semantic class relation graph, additionally supported by a semantic class dendrogram using the off-the-shelf hierarchical clustering algorithm in SciPy for better visualisation. The features for each semantic class used in both visualisations are averaged across all available pixel embeddings in each class from the validation set. In all visualisations, we present features learned with ReCo on top of supervised learning trained on all labelled data, representing the semantic class relationships of the full dataset.
The pair-wise relation graph helps us to understand the distribution of semantic classes in each dataset, and clarifies the pattern of incorrect predictions from the trained semantic network. Here, brighter colour represents a closer/more confusing pair-wise relation.
Visualisation of the semantic class relationship in dataset.
We find that all classes are perfectly disentangled in Pascal, suggesting the Pascal dataset is well-defined whose semantic objects were labelled in a consistent manner.
In this work, we have presented ReCo, a new pixel-level contrastive framework with active sampling, designed specifically for semantic segmentation. ReCo can improve performance in supervised or semi-supervised semantic segmentation methods with minimal additional memory footprint. In particular, ReCo has shown its strongest effect in semi-supervised learning with very few labels, where we improved on the previous state-of-the-art by a large margin. In further work, we aim to design effective contrastive frameworks for video representation learning.
If you found this work is useful in your own research, please considering citing the following.
@inproceedings{liu2022reco,
title={Bootstrapping Semantic Segmentation with Regional Contrast},
author={Liu, Shikun and Zhi, Shuaifeng and Johns, Edward and Davison, Andrew J},
booktitle={International Conference on Learning Representations},
year={2022},
}



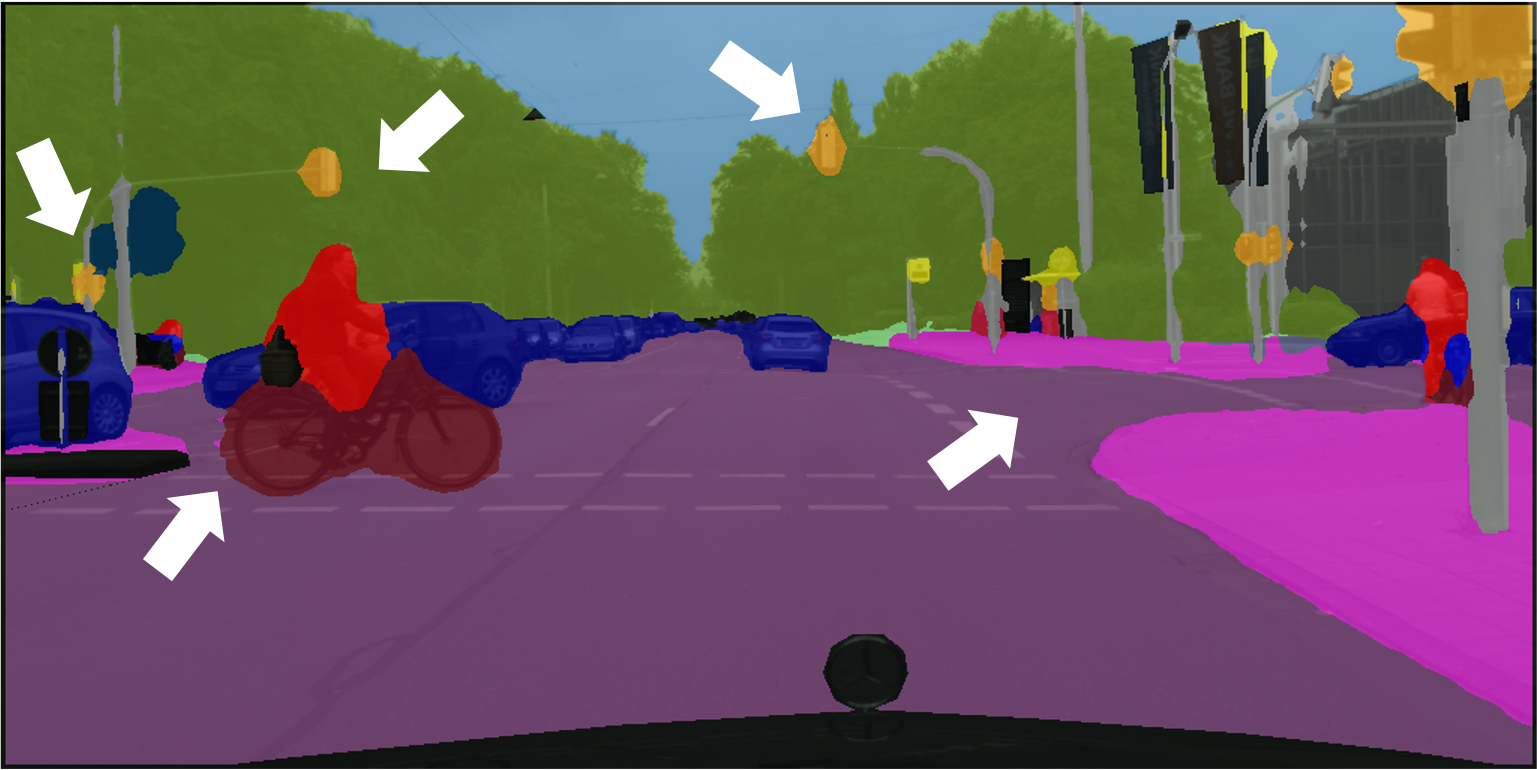
Visualisation of trained with 60 labelled images.
Ground Truth
Supervised
ClassMix
ReCo + ClassMix
Background
Aeroplane
Bicycle
Bird
Boat
Bottle
Bus
Car
Cat
Chair
Cow
Table
Dog
Horse
Motorbike
Person
Plant
Sheep
Sofa
Train
Monitor
Undefined
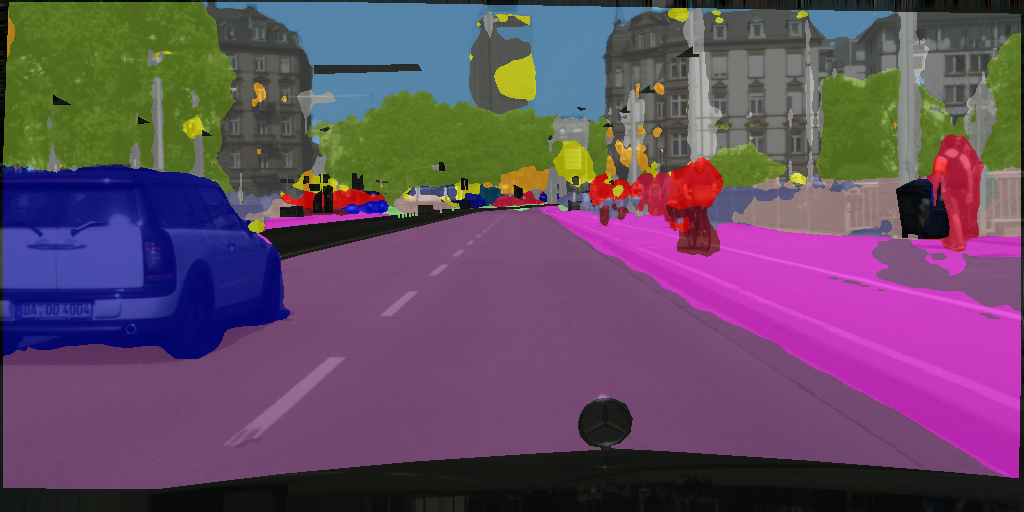
Ground Truth
Supervised
ClassMix
ReCo + ClassMix
Road
Sidewalk
Building
Wall
Fence
Pole
Traffic Light
Traffic Sign
Vegetation
Terrain
Sky
Person
Rider
Car
Truck
Bus
Train
Motorcycle
Bicycle
Undefined
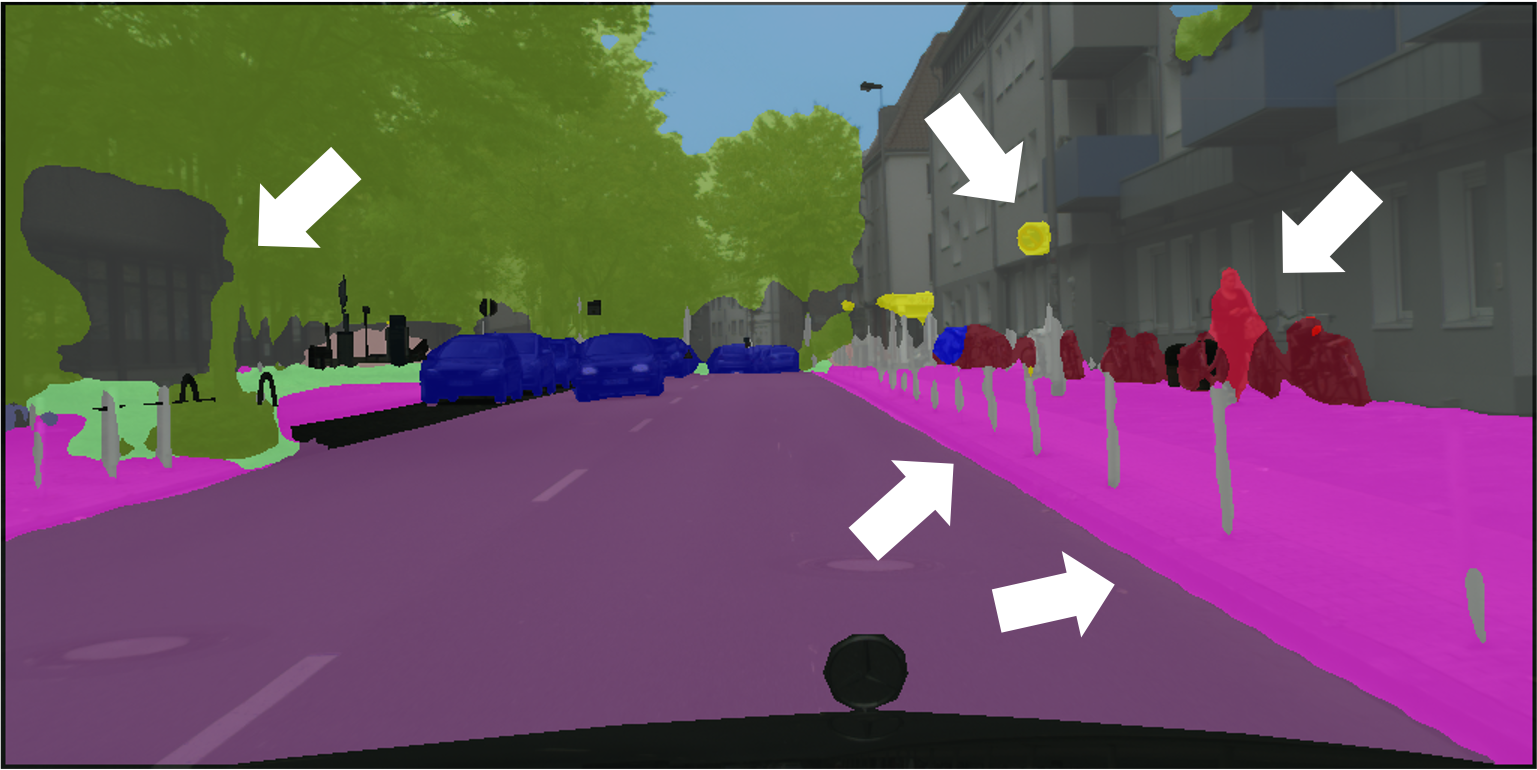
Ground Truth
Supervised
ClassMix
ReCo + ClassMix
Wall
Floor
Cabinet
Bed
Chair
Sofa
Table
Door
Window
Bookshelf
Picture
Counter
Blinds
Desk
Shelves
Curtain
Dresser
Pillow
Mirror
Floor Mat
Clothes
Ceiling
Books
Fridge
TV
Paper
Towel
Bath Curtain
Box
Whiteboard
Person
Nightstand
Toilet
Sink
Lamp
Bathtub
Bag
Undefined
In Pascal, the baselines Supervised and ClassMix are very prone to completely misclassifying rare objects such as boat, bottle and table class, while our method can predict these rare classes accurately.
In CityScapes, we can see the clear advantage of ReCo as similar to SUN RGB-D, where the edges and boundaries of small objects are clearly more pronounced such as in the person and bicycle class.
In SUN RGB-D, we can see the clear advantage of ReCo as similar to CityScapes, where the edges and boundaries of small objects are clearly more pronounced such as in the pillow and lamp class.
More interestingly, though all methods may confuse ambiguous class pairs such as table and desk or window and curtain, ReCo still produces consistently sharp and accurate object boundaries compared to the Supervised and ClassMix baselines where labels are noisy near object boundaries.