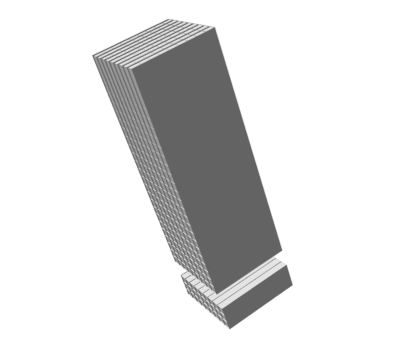
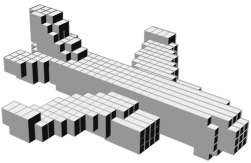
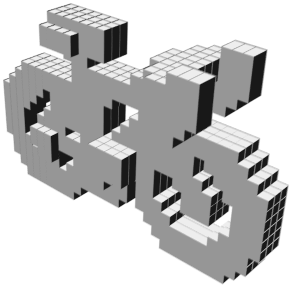
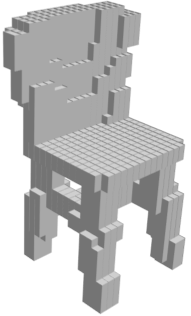
VSL: Variational Shape Learner
by Shikun Liu, C. Lee Giles, & Alexander G. Ororbia II
We present Variational Shape Learner (VSL), a hierarchical latent-variable model for 3D shape learning. VSL employs an unsupervised approach and inferring the underlying structure of voxelised 3D shapes. Realistic 3D objects can be easily generated by sampling the VSL's latent probabilistic manifold.
3DV 2018 / Oral Presentation
Introduction
We propose a novel latent-variable model, which we call the Variational Shape Learner (VSL), which is capable of learning expressive feature representations of voxelised 3D shapes. We observe impressive performance in shape generation in ModelNet dataset.
Motivated by the argument for a hierarchical representation and the promise shown
in work such as Ladder VAE and Neural Statistician, we show how to encourage a
latent-variable generative model to learn a hierarchy of latent variables through the use of synaptic skip-connections.
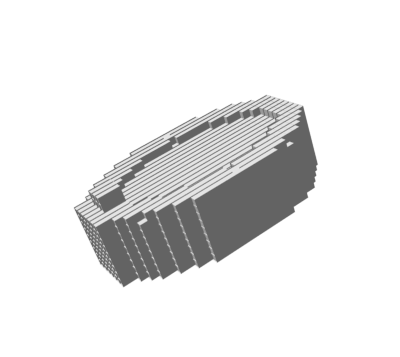
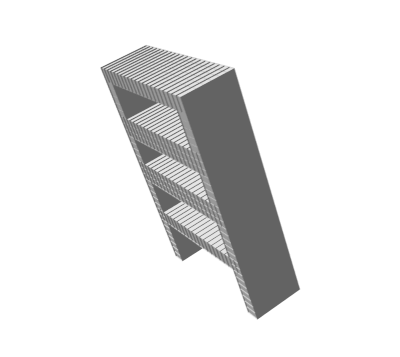
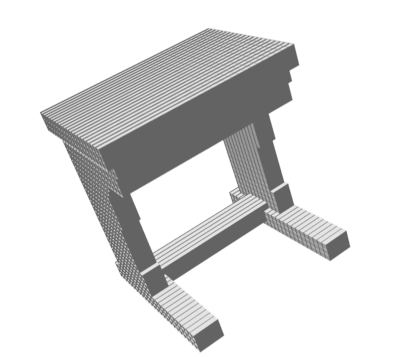
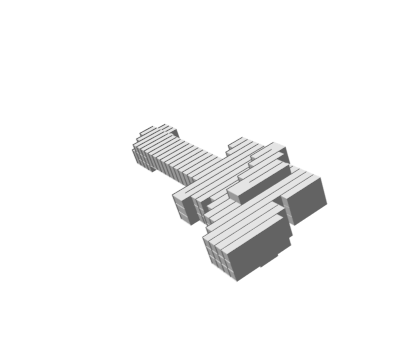
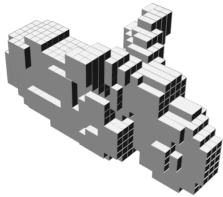
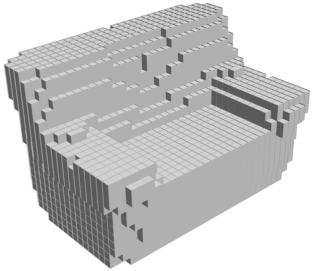
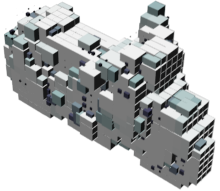
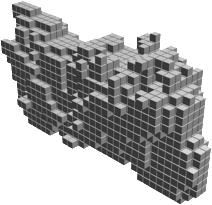
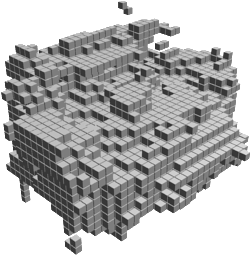
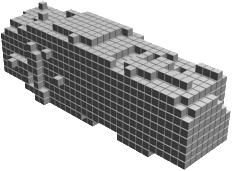
Random 3D shapes generated from VSL by sampling the learned latent space.
The Design Philosophy
Limitation of Prior Methods
Many of the previous methods require multiple images and/or additional human-provided information. Of the few unsupervised neural-based approaches that exist, one may either need multi-stage training procedure, since jointly training the system components proves to be too difficult, or employ an adversarial learning scheme. However, GANs are notoriously difficult to train, often due to ill-designed loss functions and the higher chance of zero gradients.
Why Hierarchical?
It is well known that generative models, learned through variational inference, are excellent at reconstructing complex data but tend to produce blurry samples. This happens
because there is uncertainty in the model’s predictions when we reconstruct the data from a latent space. Previous approaches to 3D object modelling have focused on learning a single latent representation of the data. However, this simple latent structure might be hindering the model’s ability to extract richer structure from the input distribution and thus lead to blurrier reconstructions.
To improve the quality of the samples of generated objects, we introduce a more complex internal variable structure, with the specific goal of encouraging the learning of a hierarchical arrangement of latent feature detectors. The motivation for a latent hierarchy comes from the observation that objects under the same category usually have similar geometric structure.
Variational Auto-Encoder
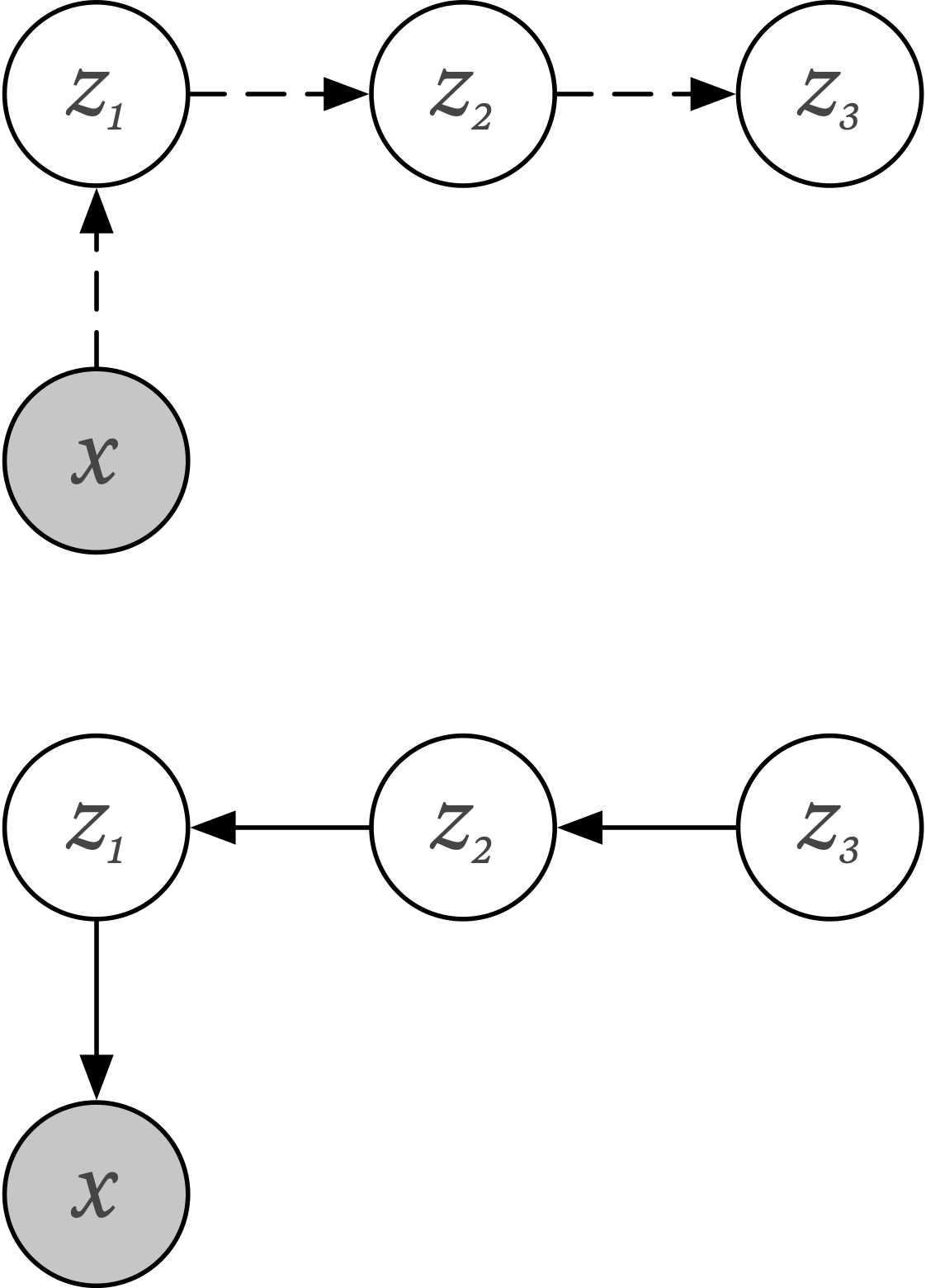
Variational Shape Learner
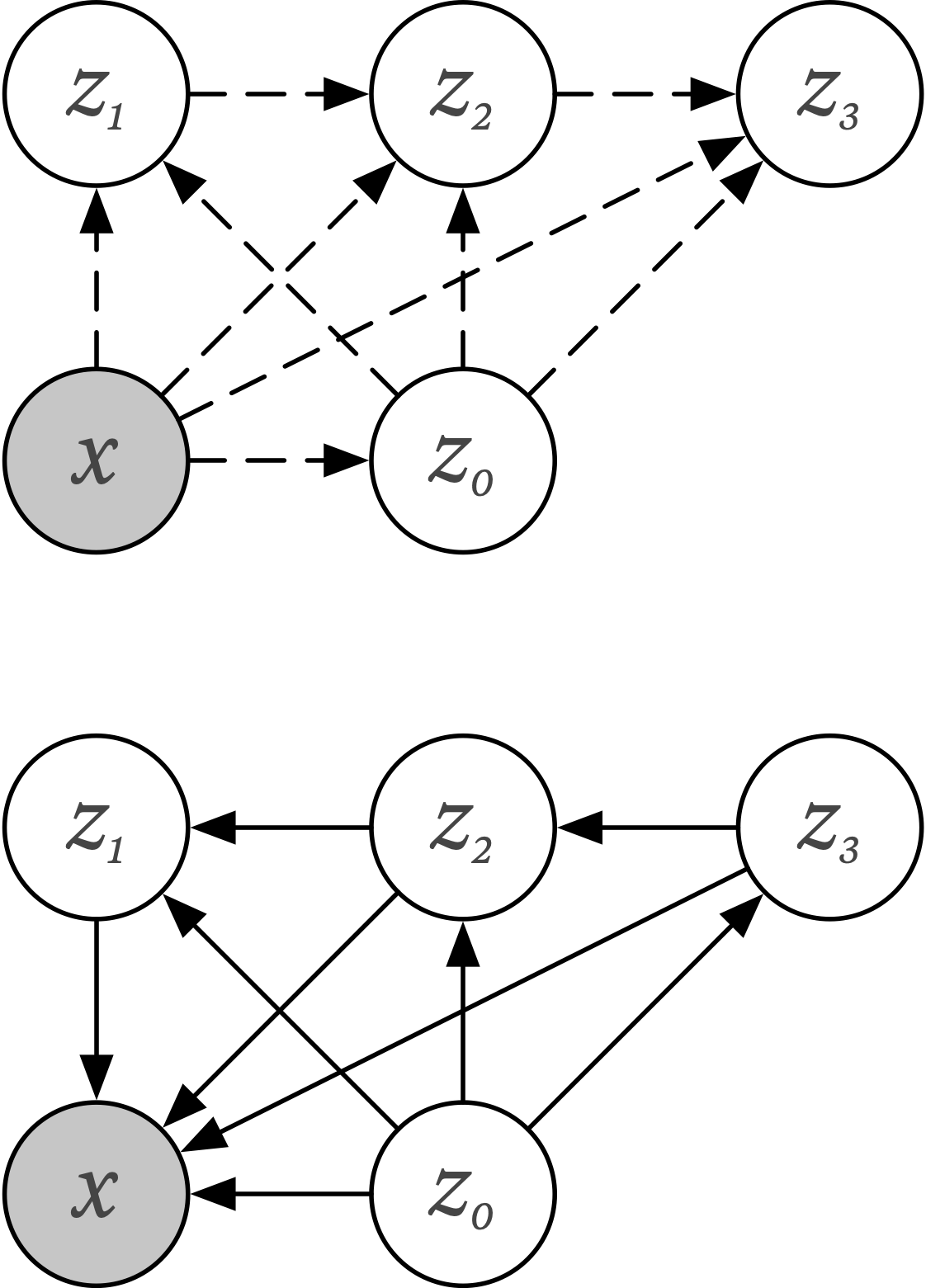
The inference (top) and generative (bottom) model for vanilla VAE and VSL. Compared to VAE, our method introduces an additional node z0, a global latent variable layer that is hardwired to a set of local latent variables layers z1-3, each tasked with representing one level of feature abstraction.
The skip-connections tie together the latent codes, and in a top-down directed fashion, local codes closer to the input will tend to represent lower-level features while local codes farther away from the input will tend towards representing higher-level features. The global latent vector can be thought of as a large pool of command units that ensures that each local code extracts information relative to its position in the hierarchy, forming an overall coherent structure. This explicit global-local form, and the way it constrains how information flows across it, lends itself to a straightforward parametrisation of the generative model and furthermore ensures robustness, dramatically cutting down on over-fitting.
Experiments and Visualisations
We conduct extensive experiments to evaluate the quality of VSL. We trained the model using ModelNet-40 dataset, except for single image shape reconstruction which applied on PASCAL3D+ dataset. In our visualisations, brighter colour corresponds to higher occupancy probability, all 3D voxels are in resolution of 303. All generated results we show here are not cherry-picked.
Single Shape Generation
To examine our model’s ability to generate high-resolution 3D shapes with realistic details, we design a task that involves shape generation and shape interpolation. We add Gaussian noise to the learned latent codes on test data taken from ModelNet4-0 and then use our model to generate “unseen” samples that are similar to the input voxel.
Shape Morphing
The results of our shape interpolation experiment, from both within-class and across-class perspectives, is presented below. It can be observed that the proposed VSL shows the ability to smoothly transition between two objects.
Unsupervised Shape Classification
Another way to test model expressiveness is to conduct shape classification directly using the learned embeddings. We evaluate the features learned on the ModelNet dataset, by concatenating both the global latent variable with the local latent layers, creating a single feature vector. We
train a Support Vector Machine with an RBF kernel for classification using these “pre-trained” embeddings.
The following table shows the performance of previous state-of-the-art supervised and unsupervised methods in shape classification on both variants of the ModelNet datasets. Notably,
the best unsupervised state-of-the-art results reported so far were from the 3D-GAN, which used features from 3 layers of convolutional networks with total dimensions over a 10 million. This is a far larger feature space than that required by our model, which is simply 35 (for 10-way classification) and 70 (for 40-way classification) and reaches the exact same level of performance.
| Method |
#Params |
Supervision |
ModelNet-10 |
ModelNet-40 |
| 3D ShapeNet |
15M |
Yes |
83.5% |
77.3% |
| DeepPano |
3.27M |
Yes |
85.5% |
77.6% |
| VoxNet |
0.92M |
Yes |
92.0% |
83.0% |
| TL Network |
< 100 |
No |
n.a. |
74.4% |
| 3D-GAN |
11M |
No |
91.0% |
83.3% |
| VSL (Ours) |
< 100 |
No |
91.0% |
84.5% |
ModelNet-10/40 classification results for both unsupervised and supervised methods.
Single Image Shape Retrieval
Real-world, single image 3D model retrieval is another application of the proposed VSL model. This is a challenging problem, forcing a model to deal with real-world 2D images under a variety of lighting conditions and resolutions. Furthermore, there are many instances of model occlusion as well as different colour gradings. To test our model on this application, we use the PASCAL 3D+ dataset and we compare our results with the recent 3D-R2N2 model.
Reconstruction samples for PASCAL 3D+ from VSL and 3D-R2N2.
Shape Arithmetic
Finally, we explore the learned embeddings by performing various vector operations on the latent space. VSL seems to generate very interesting combinations of the input embeddings without the
need for any matching to actual 3D shapes from the original dataset. The resultant objects appear to clearly embody the intuitive semantic meaning of the vector operators.
Generated samples from VSL for shape arithmetic experiment.
Conclusion
We presented the Variational Shape Learner (VSL),
a hierarchical latent-variable model for 3D shape modelling, learnable through variational inference. In particular, we have demonstrated 3D shape generation results on a popular benchmark, the ModelNet dataset. We also used the learned embeddings of our model to obtain state-of-the-art in unsupervised shape classification and furthermore showed that we could generate unseen shapes using shape
arithmetic. Future work will entail a more thorough investigation of the embeddings learned by our hierarchical latent variable model as well as integration of better prior distributions into the framework.
Citation
If you found this work is useful in your own research, please considering citing the following.
@inproceedings{liu2018vsl,
title={Learning a Hierarchical Latent-Variable Model of 3D Shapes},
author={Liu, Shikun and Giles, Lee and Ororbia, Alexander},
booktitle={2018 International Conference on 3D Vision (3DV)},
pages={542--551},
year={2018},
organization={IEEE}
}