We present MTAN, a novel multi-task architecture which allows learning of task-specific feature-level attention. Our model can be trained end-to-end and can be built upon any feed-forward neural network, is simple to implement, and is parameter efficient. We show that MTAN is state-of-the-art in multi-task learning compared to existing methods, and is also less sensitive to weighting schemes in the multi-task loss function.
Compared to standard single-task learning, training multiple tasks whilst successfully learning a shared representation poses two key challenges:
Network Architecture (how to share): A multi-task
learning architecture should express both task-shared
and task-specific features. In this way, the network is encouraged to learn a generalisable representation (to avoid over-fitting), whilst also providing the ability to learn features tailored to each task (to avoid under-fitting).
Loss Function (how to balance tasks):
A multi-task loss function, which weights the relative contributions of
each task, should enable learning of all tasks with equal
importance, without allowing easier tasks to dominate.
Manual tuning of loss weights is tedious, and it is preferable to automatically learn the weights, or design a network which is robust to different weights.
However, most prior MTL approaches focus on only one of these two challenges, whilst maintaining a standard implementation of the other. In this work, we introduce a unified approach which addresses both challenges cohesively, by designing a novel network which (i) enables both task-shared and task-specific features to be learned automatically, and consequently (ii) learns an inherent robustness to the choice of loss weighting.
The Design of MTAN
MTAN consists of two components: a single shared network, and K (number of tasks) task-specific attention networks. The shared network can be designed based on the particular task, whilst each task-specific network consists of a set of attention
modules, which link with the shared network. Each attention module applies a soft attention mask to a particular layer of the shared network, to learn task-specific features.
As such, the attention masks can be considered as feature selectors from the shared network, which are automatically learned in an end-to-end manner, whilst the shared network
learns a compact global feature pool across all tasks.
Visualisation of MTAN, showing the global / task-shared features (up) and task-specific features (down) from the encoder and decoder part of the network respectively. All attention modules have the same design across all other layers in the network, although their weights are individually learned.
Each task-specific attention module only contains two convolutional layers composed with [1 × 1] kernels, introducing very few parameters for each task. The [3 × 3] convolutional layer represents a shared feature extractor for passing to another attention module, following by a pooling or sampling layer to match the corresponding resolution.
The attention mask, following a sigmoid activation to ensure attended features to be in the range between [0, 1], is learned in a self-supervised fashion with back-propagation. If an attention mask is close to 1, such that becoming an identity map, the attended features are equivalent to global feature maps, and thus the tasks share all the features. Therefore, we expect the performance of MTAN to be no worse than that of the standard multi-task network with hard-parameter sharing, and we show results demonstrating this in the following section.
Experiments
In this section, we evaluate our proposed method on two types of tasks: one-to-many predictions for image-to-image regression tasks; and many-to-many predictions for image classification tasks.
NOTE: We suggest readers to check out this survey, offering the detailed evaluation and analysis of the current up-to-date multi-task architecture and loss function design (including MTAN built on top of a stronger backbone architecture: ResNet-50 with dilated convolution).
Baselines
Most prior multi-task learning architectures are designed based on specific feed-forward neural networks, or implemented on varying network architectures, and thus they are typically not directly comparable based on published results. Our method is general and can be applied to any feed-forward neural network, and so for a fair comparison, we implemented 5 different network architectures (2
single-task + 3 multi-task) based on the same backbone: SegNet, which we consider as baselines.
Single-Task, One Task: The vanilla SegNet for single
task learning.
Single-Task, STAN: A Single-Task Attention Network,
where we directly apply our proposed MTAN whilst only performing a single task.
Multi-Task, Split (Wide, Deep): The standard multi-task learning (hard-parameter sharing), which splits at the last layer for the final
prediction for each specific task. We introduce two versions of Split: Wide, where we adjusted the number of convolutional filters; and Deep, where we adjusted the number of convolutional layers, until Split had at least as many parameters as MTAN.
Multi-Task, Dense: A shared network together with
task-specific networks, where each task-specific network
receives all features from the shared network, without any attention modules.
Multi-Task, Cross-Stitch: The Cross-Stitch Network, a previously proposed adaptive multi-task learning approach, which we implemented on SegNet.
Dynamic Weight Average (DWA)
For most multi-task learning networks, training multiple tasks is difficult without finding the correct balance between those tasks, and recent approaches (GradNorm, Uncertainty Weighting) have attempted to address this issue. To test our method across a range of weighting schemes, we propose a simple yet effective adaptive weighting method, named Dynamic Weight Average (DWA). Inspired by GradNorm, DWA learns to average task weighting over time by considering the rate of change of loss for each task. But whilst GradNorm requires access to the network’s internal gradients, our DWA proposal only requires the numerical task loss, and therefore its implementation is far simpler.
Update: We recently developed a new and more general optimisation strategy. See Auto-Lambda for more details.
Results on Image-to-Image Predictions
The following table shows experimental results for NYUv2 datasets across all architectures. Results also show the number of network parameters for each architecture relative to single task learning. Our method outperforms all baselines across all learning tasks. Following this, we then show qualitative results on the CityScapes validation dataset. We can see the advantage of our multi-task learning approach over vanilla single-task learning, where the edges of objects are clearly more pronounced.
Type
#Params
Architecture
Segmentation (Higher Better)
Depth (Lower Better)
Surface Normal
Angle Distance (Lower Better)
Within t (Higher Better)
mIoU
Pix Acc
Abs Err
Rel Err
Mean
Medium
11.25
22.5
30
Single Task
3
One Task
15.10
51.54
0.7508
0.3266
31.76
25.51
22.12
45.33
57.13
4.56
STAN
15.73
52.89
0.6935
0.2891
32.09
26.32
21.49
44.38
56.51
Multi Task
1.75
Split, Wide
15.89
51.19
0.6494
0.2804
33.69
28.91
18.54
39.91
52.05
2
Split, Deep
13.03
41.47
0.7836
0.3326
38.28
36.55
9.50
27.11
39.63
4.95
Dense
16.06
52.73
0.6488
0.2871
33.58
28.01
20.07
41.50
53.35
3
Cross-Stitch
14.71
50.23
0.6481
0.2871
33.56
28.58
20.08
40.54
51.97
1.77
MTAN (Ours)
17.72
55.32
0.5906
0.2577
31.44
25.37
23.17
45.65
57.48
13-class semantic segmentation, depth estimation, and surface normal prediction results on the NYUv2 validation dataset with equal task wighting. Please refer to the original paper for more results on other weighting schemes.
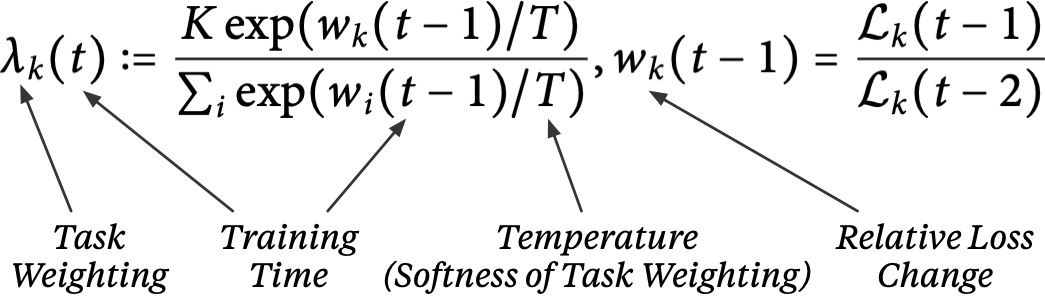
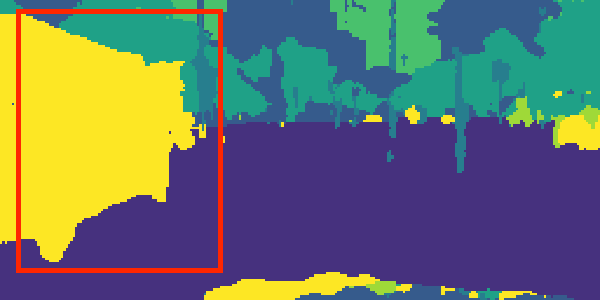
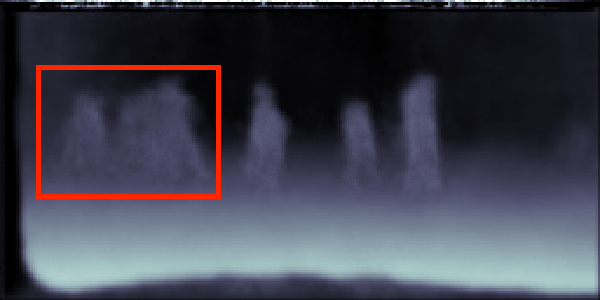
Input Image
Ground-Truth (Segmentation)
Single-Task Learning
MTAN
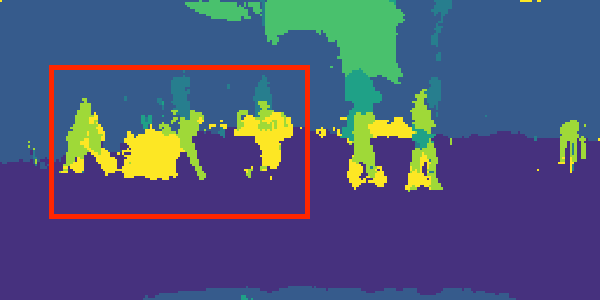
Ground-Truth (Depth)
Single-Task Learning
MTAN
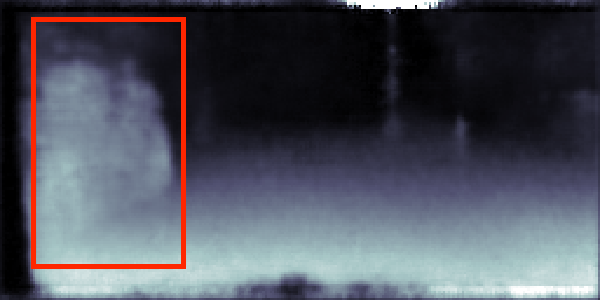
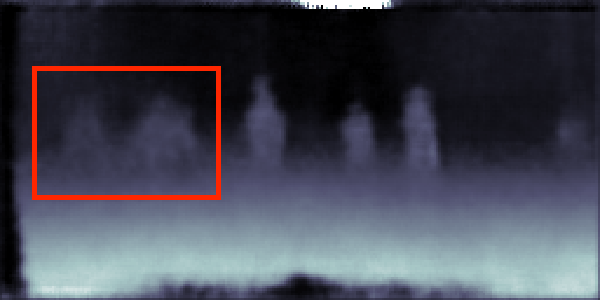
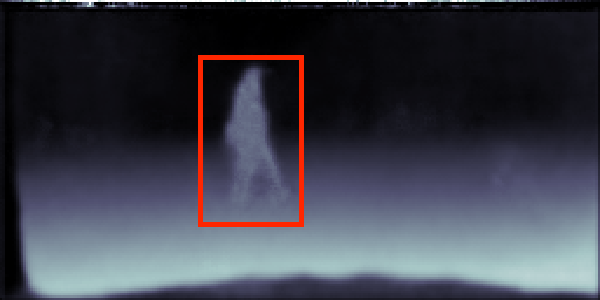
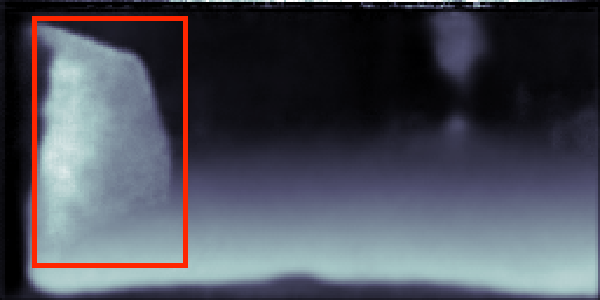
CityScapes validation results on 7-class semantic labelling and depth estimation, trained with equal weighting. The original images are cropped to avoid invalid points for better visualisation. The red boxes are regions of interest, showing the effectiveness of the results provided from our method and single task method.
Robustness to Task Weighting Schemes
MTAN maintains high performance across different loss function weighting schemes, and is more robust to the choice of weighting scheme than other methods, avoiding the need for cumbersome tweaking of loss weights. We illustrate the robustness of our method to the weighting schemes with a comparison to the Cross-Stitch Network, by plotting learning curves with respect to the performance of three learning tasks in NYUv2 dataset.
Cross Stitch Network
Multi-task Attention Network
Equal Weights Uncertainty Weights DWA
Validation performance curves on the NYUv2 dataset, across all three tasks (semantics, depth, normals,
from left to right), showing robustness to loss function weighting schemes on the Cross-Stitch Network (top)
and our Multi-task Attention Network (bottom).
Visualisation of Attended Features
To understand the role of the proposed attention modules, in the following figure we visualise the first layer attention masks learned with our network based on CityScapes dataset. We can see a clear difference in attention masks between the two tasks, with each mask working as a feature selector to mask out uninformative parts of the shared features, and focus on parts which are useful for each task. Notably, the depth masks have a much higher contrast than the semantic masks, suggesting that whilst all shared features are generally useful for the semantic task, the depth task benefits more from extraction of task-specific features.
Input Image
Shared Features
Semantic Mask
Semantic Features
Depth Mask
Depth Features
Visualisation of the first layer of 7-class semantic and depth attention features of our proposed network. The colours for each image are rescaled to fit the data.
Results on Many-to-Many Predictions (Visual Decathlon Challenge)
Finally, we evaluate our approach on the recently introduced Visual Decathlon Challenge, consisting of 10 individual image classification tasks (many-to-many predictions). Evaluation on this challenge reports per-task accuracies, and assigns a cumulative score with a maximum value of 10,000 (1,000 per task).
The following table shows results for the online test set of the challenge. As consistent with the prior works, we apply MTAN built on Wide Residual Network. The results show that our approach surpasses most of the
baselines and is competitive with the current state-of-the-art, without the need for complicated regularisation strategies such as applying DropOut, regrouping datasets by size, or adaptive weight decay for each dataset, as required.
Top-1 classification accuracy on the Visual Decathlon Challenge online test set.
Conclusion
In this work, we have presented a new method for multi-task learning, the Multi-Task Attention Network (MTAN).
The network architecture consists of a global feature pool, together with task-specific attention modules for each task, which allows for automatic learning of both task-shared and task-specific features in an end-to-end manner. Experiments on the NYUv2 and CityScapes datasets with multiple dense-prediction tasks, and on the Visual Decathlon Challenge with multiple image classification tasks, show
that our method outperforms or is competitive with other methods, whilst also showing robustness to the particular
task weighting schemes used in the loss function. Due to our method’s ability to share weights through attention masks, our method achieves this state-of-the-art performance whilst also being highly parameter efficient.
Citation
If you found this work is useful in your own research, please considering citing the following.
@inproceedings{liu2019mtan,
title={End-to-End Multi-task Learning with Attention},
author={Liu, Shikun and Johns, Edward and Davison, Andrew J},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={1871--1880},
year={2019}
}